核心问题
RAG 要先“找资料”,但机器怎样知道哪段资料和你的问题意思相近?你问“休假怎么申请”,文档标题可能叫“员工请假与考勤流程”;你问“发票怎么走流程”,制度里可能写的是“报销材料提交规范”。字面不完全一样,意思却相关。
Embedding 的作用,就是把文字转换成表示“意思位置”的向量,让机器可以按语义相似度查找资料。
先建立直觉
想象一个图书馆管理员,不是只按书名里的字查找,而是能理解主题。你说“孩子晚上睡不好”,他可能推荐睡眠习惯、儿童心理、卧室环境相关的书,而不是只找标题里含“孩子、晚上、睡不好”的书。
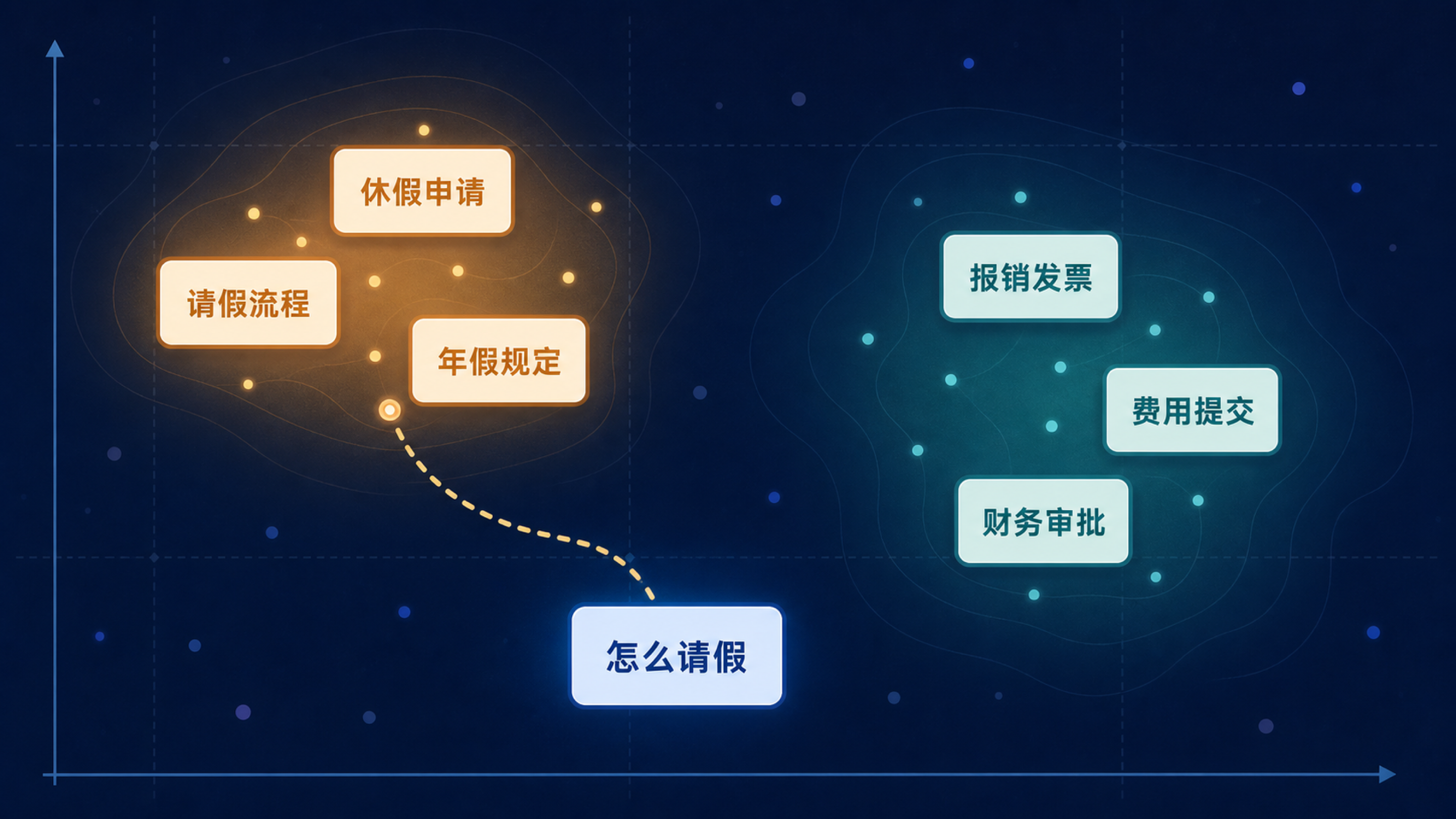
Embedding 就像给每段文字安排一个语义坐标。意思相近的内容会在空间里靠近,意思不同的内容会离得较远。这样系统就可以把用户问题和文档片段放到同一个空间里,寻找最近的资料。
概念拆解
Embedding 是一串数字,也叫向量。普通人不需要记住它有多少维,只要理解它的用途:把文字的含义变成可以比较距离的数字表示。
在 RAG 中,系统会提前把知识库里的文档切成片段,并为每个片段生成 embedding。用户提问时,系统也把问题生成 embedding,然后找距离最近的文档片段。距离近,表示语义上更相似。
这和关键词搜索不同。关键词搜索依赖字面匹配,适合找精确词;embedding 检索更擅长找意思相近的表达。但它也不是万能的。如果问题非常依赖精确数字、条款编号、人名、日期,关键词和结构化过滤仍然重要。
互动理解
下面的地图用二维空间简化展示语义距离。真实 embedding 维度更高,但直觉相同:意思相近的内容被放得更近。
语义坐标地图
Embedding 会把意思相近的句子放得更近,而不是只看字面是否相同。
报销流程
财务:发票、审批、付款
低相关 · 距离 52
请假制度
人事:申请、主管、考勤
高相关 · 距离 5
年假余额
人事:休假、额度、结转
高相关 · 距离 4
服务器告警
技术:监控、故障、恢复
低相关 · 距离 48
常见误区
第一个误区是把 embedding 想成真正理解。它能捕捉语义相似,但不代表懂业务规则。两段话意思接近,不等于它们都能回答当前问题。
第二个误区是忽略切片。文档切得太大,片段里混入太多无关内容;切得太碎,又可能丢掉上下文。RAG 效果经常卡在切片质量上。
第三个误区是只用向量检索。很多企业文档需要同时按权限、时间、部门、文档类型过滤。否则检索结果可能语义相近,但不适用于当前用户。
实用方法
判断一个 embedding 检索系统是否好用,可以看三点。
第一,它能不能找到同义不同字的内容,比如“年假”和“休假余额”。第二,它能不能避免找来语义相近但场景不对的材料。第三,它能不能和关键词、权限、时间等过滤条件配合使用。
普通用户不必直接操作 embedding,但理解它能帮你判断 RAG 的边界:检索不是模型凭空知道,而是系统先按语义找资料。资料找错了,后面回答再漂亮也会偏。
自我检查
可以把“语义相近”和“答案相关”分开看。你问“病假需要什么证明”,系统找到“年假余额查询”可能都属于人事主题,但并不能回答病假证明。语义近只是候选,不是最终答案。
在企业知识库里,真正好的检索往往是混合的:先用权限和部门过滤,再用关键词锁定专有名词,再用 embedding 找表达相近的片段。只靠一种检索方式,容易在真实复杂资料中出错。
真实场景
一个员工问“我家里有事能不能请几天假”,embedding 可能找到“事假制度”“年假规则”“病假材料”三个相近片段。系统还需要结合员工所在地区、合同类型和公司最新政策,才能判断哪段最适用。语义相近只是第一步,业务适用性才是最终目标。
这也是为什么很多 RAG 系统要保留原文链接。用户看到答案后,可以回到制度原文确认适用范围,而不是只相信摘要。
Embedding 最适合作为“找候选资料”的入口,而不是最终裁判。最终是否采用某段资料,还要看来源可信度、更新时间、权限范围和问题意图。把这几层分开,RAG 的错误会更容易定位。
当答案出错时,也可以顺着链路排查:是问题向量不准,还是文档切片太差,还是相似片段不适用,还是模型读错了原文。Embedding 只是链路中的一环。
把链路拆开,才不会把所有问题都误判成“模型不够聪明”。
真正可维护的 AI 系统,一定能区分检索问题、资料问题、权限问题和生成问题。
延伸阅读
- Embedding 是 RAG 检索的核心机制——回到第 13 章:RAG看完整管线
- Embedding 也是把文字变成模型可计算的数字表示,这和第 5 章:Token讲的文字转换是同一个方向上的不同层次
一句话总结
Embedding 把文字放进语义空间,让机器按意思找资料;它擅长相似查找,但仍需要切片、过滤和人工校验配合。