核心问题
为什么模型有时会拒绝危险请求?为什么它不只是“用户让做什么就做什么”?这背后是对齐。对齐的目标,是让模型在有能力的同时,更符合人类使用场景中的帮助性、诚实性和安全边界。
如果没有对齐,一个强大的生成模型可能会顺着任何请求写下去,包括违法、危险、伤害他人或误导用户的内容。对齐不是让模型变得没用,而是让它知道什么时候该回答、什么时候该拒绝、什么时候该给安全替代方案。
先建立直觉
培养一个专业助手,不只是让他读很多书。读书让他有知识,但还不够。你还要教他如何按指令工作、如何判断风险、如何在不确定时说不知道、如何拒绝不合适的要求。
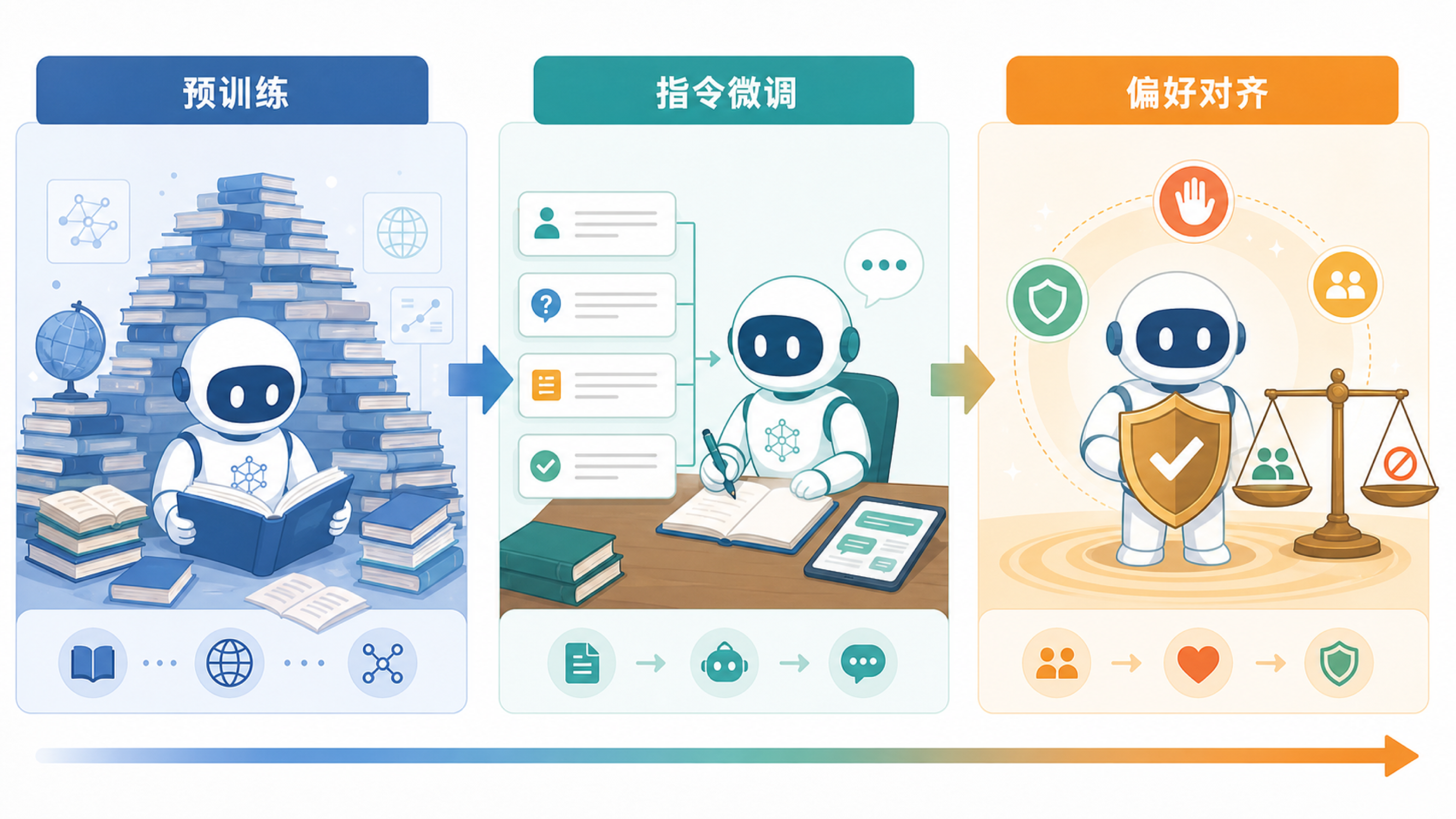
模型训练也类似。预训练让模型学会大量语言模式;指令微调让它学会按用户请求回答;偏好对齐让它学习怎样的回答更有帮助、更诚实、更安全。
概念拆解
对齐通常发生在后训练阶段。模型先通过预训练成为基座模型,具备续写和模仿能力;再通过监督微调学习“问题到答案”的行为格式;然后通过人类偏好反馈、规则数据、安全评估等方式,学习更合适的行为边界。
例如,用户要求“帮我绕过门禁”,一个未对齐模型可能顺着写危险步骤;经过对齐的助手应该识别风险,拒绝提供可执行伤害步骤,并转向合规建议,比如联系管理员、补办权限或说明安全制度。
对齐不是一次完成的。现实中的风险场景很多,用户表达也会变化,模型需要持续评估和改进。
互动理解
下面的组件展示同一个高风险请求在不同训练阶段可能出现的回答差异。重点看:能力和边界是两件都要训练的事。
模型训练三阶段
同一个高风险请求,在不同训练阶段会出现完全不同的回应方式。
偏好对齐阶段
模型识别出请求存在风险,拒绝提供伤害性做法,并改为提供合规替代建议。
常见误区
第一个误区是把拒绝等同于模型变笨。很多拒绝是有意设计的安全行为,尤其涉及违法、伤害、自残、隐私侵犯、危险操作时。
第二个误区是认为对齐可以解决所有风险。对齐能降低有害输出,但不能保证模型永远判断正确。它可能过度拒绝,也可能漏掉隐蔽风险。
第三个误区是要求模型展示危险中间态来“证明懂”。在安全主题里,不能为了讲解能力而提供可执行危险步骤。安全解释应该聚焦原理、风险和合规替代方案。
实用方法
使用大模型时,可以用边界意识判断回答是否合适。
如果问题涉及伤害他人、违法规避、隐私泄露、绕过安全系统,模型应该拒绝具体执行步骤,并提供安全替代建议。如果问题涉及医疗、法律、投资,它可以解释概念、整理问题清单,但不能替代专业人士做最终决策。
对齐不是阻碍,而是让 AI 更适合进入真实世界。一个只会服从的模型很危险;一个能解释、能拒绝、能转向安全帮助的模型,才更像可靠助手。
自我检查
判断一次拒绝是否合理,可以看它是否做到三点:说明不能帮助的原因,不提供可执行危险步骤,给出安全替代方向。例如不能教人绕过门禁,但可以建议联系管理员、补办权限或说明合规流程。
也要警惕过度拒绝。如果你只是想了解网络安全防护原理,模型应该可以解释概念、风险和防御方式,而不是拒绝所有相关讨论。好的对齐不是回避知识,而是把知识放在安全用途里。
真实场景
同样是“门禁系统”,询问“如何提高门禁安全审计”是防御性问题,模型可以解释权限管理、日志、异常告警;询问“如何绕过门禁进入资料室”则应拒绝具体步骤。区别不在关键词,而在意图、用途和潜在伤害。
对齐难就难在这里:模型既不能把所有敏感词都封死,也不能对明显危险请求过度配合。它需要在帮助和安全之间做保守判断。
在产品里,对齐还需要和用户体验配合。一个好的拒绝不应该只说“不行”,而应该解释风险、给出安全方向、必要时建议寻求专业帮助。这样用户既知道边界,也知道下一步可以怎么做。
对齐还会影响组织信任。如果一个助手既能在低风险任务中充分帮助,又能在高风险任务中守住边界,用户才更容易长期依赖它。安全不是附加功能,而是产品可用性的一部分。
在真实产品里,对齐、权限和审核应该一起设计。模型拒绝危险请求,系统限制危险工具,人类复核关键结果,这三层共同构成安全边界。
对普通用户来说,也可以把这种边界带入日常使用:让模型解释风险可以,让模型替你做不可逆决定不可以。
能帮忙和能负责,是两件不同的事。
对齐就是把这条线写进模型行为里。
延伸阅读
- 回顾本单元的核心线索和关键收获 → 第四单元总结
- 对齐是模型安全行为的重要保障——第 23 章:大模型是怎样训练出来的把 RLHF 放在完整训练流程中讲解
- 即使有 RAG 和 Embedding,幻觉仍然可能存在,再次回顾第 12 章:幻觉理解残存风险
一句话总结
对齐让模型不只是有能力回答,还要学会在风险场景中拒绝、保守和给出安全替代方案。