核心问题
你使用的 AI 助手不是天生就会回答问题。它经历了一个漫长训练过程:先从海量文本中学语言和知识,再通过后训练学会按指令做事、在特定能力上变强,并学习安全边界。
更重要的是,今天很多模型差异不只来自“预训练看了多少资料”,还来自后训练阶段怎么设计。SFT 教格式,RL 练专精,RLHF 定边界。
先建立直觉
培养一个专业人才,通常不是只让他读书。第一步是给他大量学习材料,让他建立知识基础。第二步是做岗前培训,让他知道面对用户请求应该怎样回应。第三步是大量练习,做题、写代码、接受反馈。第四步是职业规范训练,知道什么该说、什么不该说,什么时候必须保守。
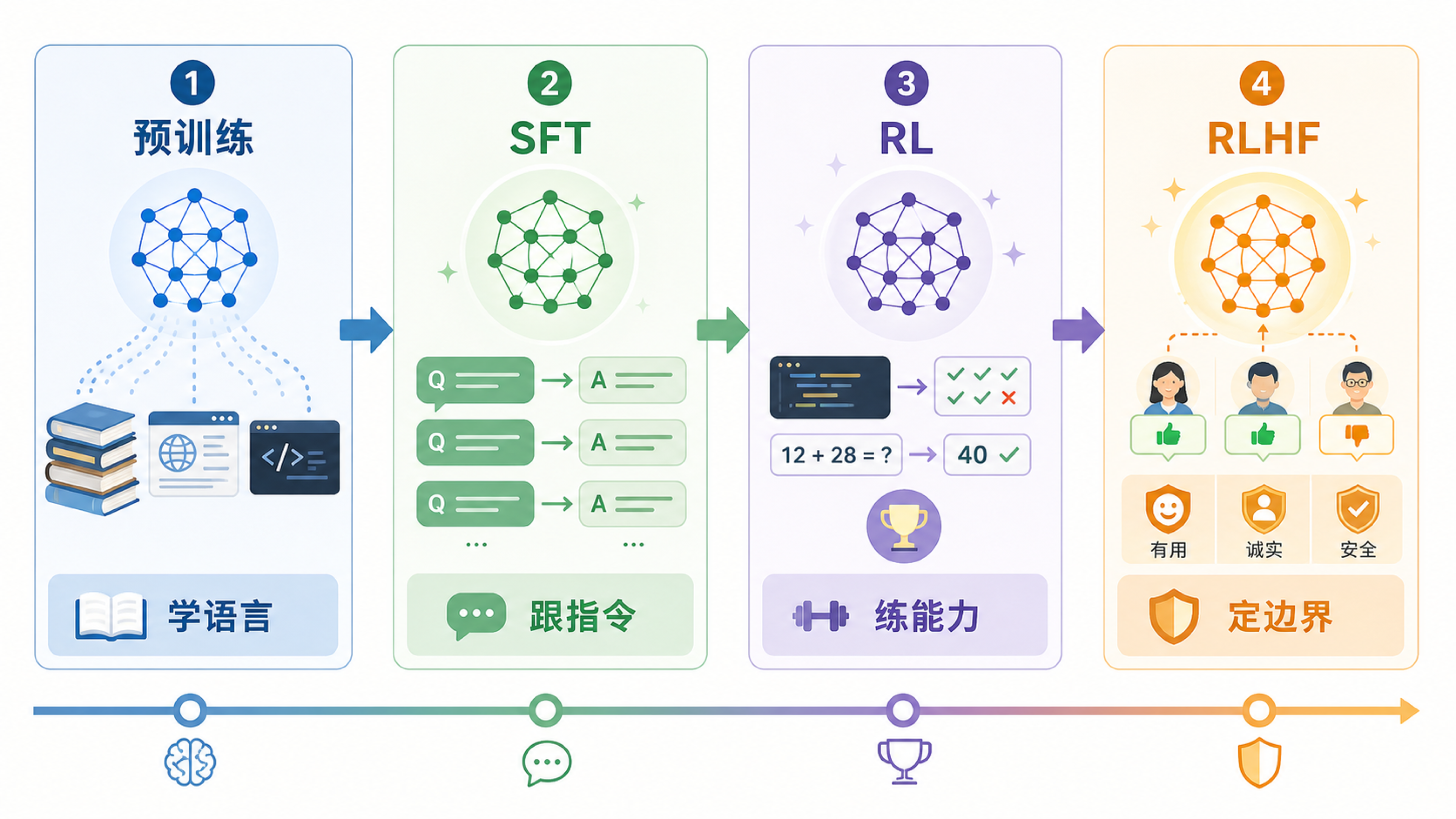
训练大模型也是类似。预训练像广泛阅读,后训练像把“会说话的毕业生”训练成“能干活的助手”。
概念拆解
预训练阶段,模型在海量文本上学习预测下一个 token。它从网页、书籍、代码、论文、论坛等材料中学到语言模式、常识关联和基础能力。预训练结束后得到的是基座模型。基座模型会续写,但不一定会像助手一样回答问题。预训练消耗的资源最大、时间最长,一个千亿参数级别的模型可能需要数千张 GPU 运行数周甚至数月。
预训练数据的质量直接影响基座模型的上限。如果训练数据里错误信息多、偏见明显、语言分布不均衡,基座模型就会带上这些问题。这也是为什么近年越来越多团队在数据清洗和配比上投入巨大精力——预训练决定了模型的能力天花板,后训练只能在这个天花板之下做调整。
SFT,也就是监督微调,会给模型大量”问题 → 理想答案”的示范。它让模型学会遵循指令、按格式回答、理解用户意图。没有这一步,模型可能更像续写器,而不是助手。SFT 数据通常由人类专家或高级模型生成,质量比数量更重要。几千条高质量示范可能比几十万条粗糙数据更有效。
RL,也就是强化学习,会让模型在可验证任务上反复尝试。代码可以跑测试,数学可以核对答案,推理可以用奖励信号训练。很多模型在代码、数学和复杂推理上的差异,就来自后训练中对这些能力的投入。RL 的关键在于奖励信号必须准确。如果奖励函数有漏洞(比如只奖励”回答长”却不管对不对),模型会学会钻空子,而不是真正变强。
RLHF,也就是从人类反馈中强化学习,会让模型学习人类偏好:更有帮助、更诚实、更安全。它不是让模型一味拒绝,而是在帮助性和安全性之间做平衡。人类标注员会对不同回答打分,模型学习这些偏好后,输出更符合使用者的预期。RLHF 的效果取决于标注员的素质和评估标准的设计——如果标注标准模糊或标注员之间不一致,模型学到偏好也会不稳定。
除了这四个核心阶段,还有一种常见的训练方式叫微调。微调不是从头训练一个新模型,而是在已有模型基础上,用少量特定领域数据继续训练,让它在某个窄任务上表现更好。如果把预训练比作通识教育,SFT 比作岗前培训,微调就像给一个已经能干的员工做专项进修——只学这一块,学完立刻用。
微调在实际场景中很常见。比如一个通用模型可能勉强能做中英翻译,但面对医学文献就频频出错。如果用一批高质量的医学中英对照文本做微调,模型在医学术语、句式、缩写上的准确率会明显提升。电商客服场景也一样:用几百条"客户问题 → 按企业话术的标准回复"做微调,模型就能更准确地遵循退换货政策、语气规范和品牌用语,而不是给出泛泛的客服话术。
微调和 Prompt 的区别很重要。微调改的是模型本身的参数,适合"领域明确、格式固定、数据干净"的重复性任务。Prompt 改的是输入上下文,适合"任务多变、临时调整、快速试验"的场景。前者像给员工安排专项培训,后者像给员工一份详细的当日任务说明。大多数普通用户不需要做微调——好的 Prompt 已经能满足日常需求。但当你在某个垂直领域反复使用 AI、积累了足够的高质量反馈数据时,微调可能是从"通用好用"到"领域精通"的升级路径。
不过微调不是万能药。如果训练数据太少、质量太差、或者和实际使用场景偏差大,微调后模型可能反而变差。它也解决不了基座模型的根本缺陷——微调是在现有能力上做加强和定向,不是无中生有。所以微调前要先评估:现有的 Prompt 方案是不是已经够用?积累的领域数据够不够干净、够不够多?任务是否真的需要模型内化这些知识,还是用 RAG 配合 Prompt 也能达到类似效果?
互动理解
下面的时间线把训练过程拆成阶段。点击每一步,重点看它的目标、输入材料和产出行为。
大模型训练四阶段
点击每个阶段,了解一个可用的大模型助手经历了怎样的训练过程。
第 1 步:数据准备
目标
决定模型能看到什么材料
输入材料
网页、书籍、论文、代码、对话等原始数据
产出行为
清洗后的训练语料
收集海量文本:网页、书籍、论文、代码、对话记录。数据需要清洗去重,剔除低质量和有害内容。这一步决定了模型的知识广度和语言基础。
像给一个学生准备图书馆——书的质量和多样性直接影响他将来能学到什么。
常见误区
第一个误区是以为预训练后模型就能直接当助手。基座模型可能很会续写,但不一定会遵循指令,也不一定知道安全边界。
第二个误区是以为 RLHF 只是让模型拒绝更多。好的偏好对齐不是一味拒绝,而是在有帮助、诚实和安全之间取平衡。
第三个误区是只看模型参数大小。后训练数据质量、奖励设计、评估体系和工具生态,同样会影响最终体验。
实用方法
理解训练流程后,看模型能力可以更具体。
如果一个模型代码强,可能是后训练中用了大量可验证代码任务。如果一个模型安全边界稳定,可能是偏好对齐和安全评估做得更细。如果一个模型对话自然,SFT 数据和偏好数据可能质量较高。
普通人不必掌握训练算法,但要知道:模型不是单靠“读过很多资料”变成助手的。它需要经过多阶段训练,才能从会续写变成能按指令协作。
自我检查
以后看到模型发布说明,可以尝试分辨它强调的是哪一段训练:说“更大语料、更长上下文”,多半和预训练或架构有关;说“代码通过率提升”,可能和可验证任务的 RL 有关;说“更少有害输出、更会拒绝风险请求”,通常和对齐训练有关。
理解训练流程后,也能更客观看待模型差异。一个模型不是所有方面都强。它在哪些数据上训练、后训练奖励什么、评估什么,都会塑造它最终擅长的任务。
真实场景
如果一个模型在编程题上很强,背后通常不只是“读过很多代码”,还可能经过大量自动化测试反馈训练。测试通过给奖励,测试失败给惩罚,模型逐渐学会生成更可运行的代码。数学推理、工具使用和多模态能力,也可能通过类似的后训练流程强化。
这解释了为什么模型发布时会强调不同 benchmark。它们不是单纯炫耀分数,而是在展示后训练塑造出的能力侧重点。
不过 benchmark 也不是全部。真实使用还要看延迟、成本、工具生态、安全边界和长任务稳定性。训练决定模型底子,产品工程决定它能不能在你的场景里稳定工作。
所以评价模型时,既要看训练带来的能力,也要看应用层是否把能力接好了。
没有好的产品工程,再强的模型也可能难用;没有好的训练底座,再漂亮的界面也撑不住复杂任务。训练和产品是两条腿,缺一条都走不稳。
看懂这条分工,就不会把所有体验差异都归因于模型参数大小。一个模型回答得好,可能是因为预训练数据覆盖了这个领域,也可能是因为 SFT 数据里有类似的问答对,也可能是因为 RL 奖励了这个方向的正确率。反过来,一个模型在某个任务上表现差,也不一定是"不够聪明",可能只是这个任务在后训练中优先级不高。把"好"和"差"归因到具体环节,才能做出有效的改进判断,而不是笼统地说"这个模型不行"。
延伸阅读
一句话总结
大模型训练不是一步完成:预训练打地基,SFT 教格式,RL 练专精,RLHF 定边界,后训练决定了模型能否真正好用。