核心问题
除了 ChatGPT、Claude、Gemini 这类商业闭源模型,为什么还有 Llama、Qwen、DeepSeek、Mistral 等开源模型?什么时候该用开源模型,什么时候继续用商业模型更省心?
答案不是谁绝对更强,而是谁更适合你的场景。模型选择是一组取舍:能力、成本、隐私、部署难度、稳定性和可控性。
先建立直觉
选模型像选交通工具。高铁速度快、服务稳定,但路线固定;私家车更自由,但你要自己维护;自行车便宜灵活,但不适合长途高速。没有一个交通工具适合所有场景。
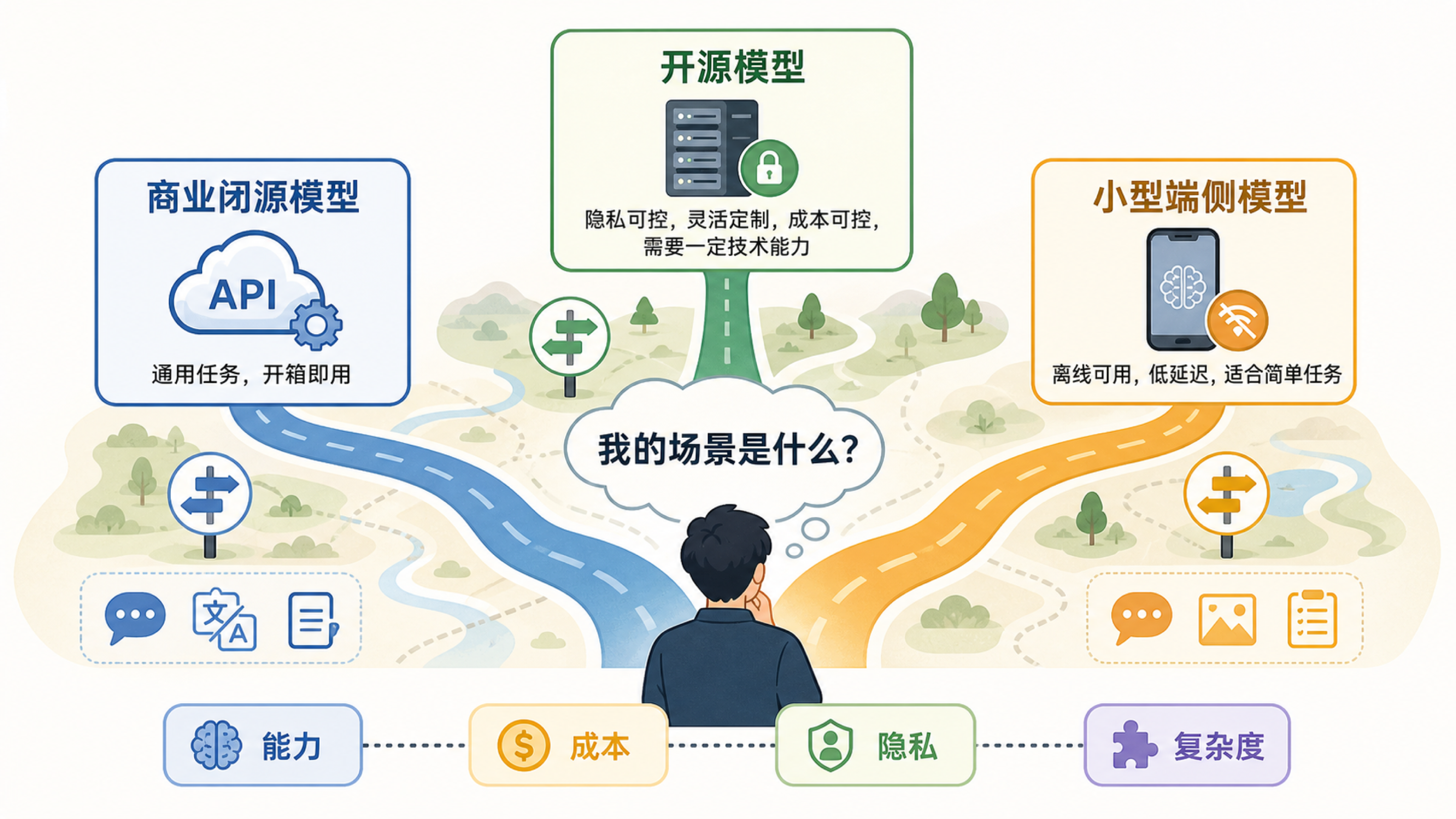
商业闭源模型像成熟服务:开箱即用、能力强、更新快、生态完善。开源模型像可以自己部署和改装的工具:更可控、更适合私有化和定制,但需要技术能力、硬件成本和运维经验。
概念拆解
闭源商用模型的优势是省心。你通常不用部署,不用管理 GPU,不用处理推理服务,只要通过网页或 API 使用。它们的通用能力、产品体验和安全体系通常也更成熟。
开源模型的优势是可控。你可以在本地或自己的服务器运行,数据不必发送给外部平台;可以针对特定任务微调;可以控制版本,避免模型突然下线或行为大变;在高频固定任务上,长期成本可能更低。
但开源不等于免费。硬件(GPU 服务器或云实例)、部署(推理框架、容器化)、优化(量化、缓存、批处理)、监控(延迟、错误率、成本)、安全(权限、审计、防注入)、更新(模型升级、补丁)都需要人力和资金。一个粗略的估算:用开源模型自建一个面向几百人的内部问答系统,即使模型本身免费,服务器、运维和开发成本每月也可能从几千到几万元不等。小型团队如果没有专门的工程能力,直接使用商业模型的 API 通常更划算。
几个主流开源模型各有侧重。Llama 系列生态最成熟,工具链和社区支持丰富,适合通用场景。Qwen 系列中文能力突出,对中文语境和本土知识覆盖更好。DeepSeek 系列在编程和推理上有特别优化,适合技术类任务。Mistral 系列以小而精著称,中小尺寸模型在同体量中表现优秀。选开源模型时,除了看排行榜,更要看它在你的语言、你的任务、你的数据格式上是否稳定——一个英文排行榜领先的模型,处理中文合同时可能不如一个中文优化的模型。
互动理解
下面的选择矩阵可以按隐私、成本、部署能力、稳定性和前沿能力切换优先级。重点看:不同优先级会导向不同模型选择。
开源模型类型速览
点击卡片,了解每种开源模型适合什么场景、有什么局限。
当前优先考虑:隐私。推荐先看 小型端侧模型,再结合实际任务测试。
通用对话模型
- 代表模型
- Llama、Qwen、DeepSeek、Mistral
- 最适合
- 日常对话、写作、总结、翻译
- 局限性
- 部分模型在中文理解上不如商业闭源模型。
常见误区
第一个误区是把开源等同于更安全。开源模型可以本地运行,数据更可控,但安全取决于部署方式、权限管理、日志和使用流程。
第二个误区是只看排行榜。排行榜能提供参考,但你的真实任务、语言环境、延迟要求、成本结构和合规要求更重要。
第三个误区是忽略小模型。不是所有任务都需要最强大模型。离线摘要、简单分类、端侧助手、隐私敏感预处理,可能小模型更合适。
实用方法
可以按场景做选择。
日常写作、翻译、总结、聊天,且不涉及敏感数据时,商业模型最省心。企业内部数据、私有部署、定制行为、成本可控要求高时,可以评估开源模型。手机端离线处理、本地文档辅助、弱网环境使用时,可以考虑小型端侧模型。
真正稳妥的做法是用小样本任务评测,而不是只看宣传。拿你自己的材料、自己的输出要求、自己的风险边界测试模型,比较准确率、速度、成本和可维护性。
一个实用的选择框架可以分五步。第一步,明确场景:是个人日常使用、团队内部协作、还是面向客户的产品功能?第二步,评估敏感度:数据是否涉及隐私、商业秘密、合规要求?是否必须离线处理?第三步,估算规模:每天大约多少次调用?高峰期并发多少?对延迟的容忍度是多少秒?第四步,盘点能力:团队有没有部署、运维、监控模型的技术能力?有没有专门的预算?第五步,用小样本跑对比:用 15-20 条真实任务测试至少两个候选方案,比较准确率、速度、成本和稳定性。这五步做完,选择通常会比看排行榜清晰得多。
对于大多数个人用户和中小团队来说,先从商业模型 API 开始是最省心的起步方式。当调用量增长、任务类型稳定、对隐私或成本有了更具体的要求时,再评估是否需要引入开源模型或混合架构。选模型不是信仰问题,而是随着业务阶段变化的工程取舍。
自我检查
选模型前,可以列一个小表:数据是否敏感?是否必须离线?每天调用量多大?团队有没有部署能力?答案错了会造成什么后果?这些问题比“哪个模型最火”更重要。
如果只是个人学习和日常写作,优先选省心工具。如果是企业内部知识问答,要重点看隐私、权限、RAG 和审计。如果是端侧功能,要重点看速度、体积和离线能力。模型没有统一最优,只有场景最优。
真实场景
一家小公司要做客服助手,前期可能直接用商业模型最快,因为产品还在验证;当调用量变大、问题类型稳定、隐私要求提高时,再评估开源模型和私有化部署。反过来,如果团队没有运维能力,过早自部署可能把精力耗在服务器和推理优化上。
选模型不是一次性决定,而是随业务阶段变化的工程取舍。
真正成熟的策略通常是组合使用:商业模型处理开放复杂任务,开源模型处理内部可控任务,小模型处理端侧和高频轻量任务。不要把模型选择做成信仰问题,把它做成评估和迭代问题。
评估时可以准备一组固定样例:常见问题、边界问题、失败案例和真实材料。每次换模型都跑同一组样例,比较质量、速度、成本和可解释性。这样选择才不会被单次惊艳回答带偏。
模型生态变化很快,但评估原则相对稳定:用自己的任务测试,用自己的风险标准判断,用持续迭代替代一次性押注。
这也是普通人学习开源模型时最该记住的事:不要被名字淹没,先从自己的需求出发,再回头选择合适的模型、部署方式和使用流程。
模型世界会继续变化,但以任务为中心的选择方法不会过时。
先定义问题,再选择模型;先跑小样本,再决定长期方案。这比追逐热点更可靠。
延伸阅读
- 回顾本单元的核心线索和关键收获 → 第七单元总结
- 选择模型的过程可以反过来看训练过程——第 23 章:大模型是怎样训练出来的帮你理解模型能力差异从何而来
- 蒸馏技术让开源小模型更实用——第 22 章:蒸馏
一句话总结
商业模型省心,开源模型可控;选模型不是追求最强,而是匹配隐私、成本、能力和部署条件。