核心问题
我们平时说话以“字、词、句子”为单位,但大模型读写文字时,真正处理的是 token。Token 可以是一个汉字、一个英文单词、一段词根、一个标点,甚至只是单词的一部分。理解 token,是理解上下文窗口、费用、生成速度和长文本处理的入口。
如果不知道 token,你会很难理解为什么同样是“一篇文章”,中文、英文、代码、表格的消耗不同;也很难理解为什么长对话会变贵,为什么模型回答越长成本越高。
先建立直觉
可以把 token 想成模型眼里的文字积木。人类读一句话时,会直接看到完整意思;模型处理时,会先把文字拆成一个个小块,再根据这些小块和上下文预测下一块。
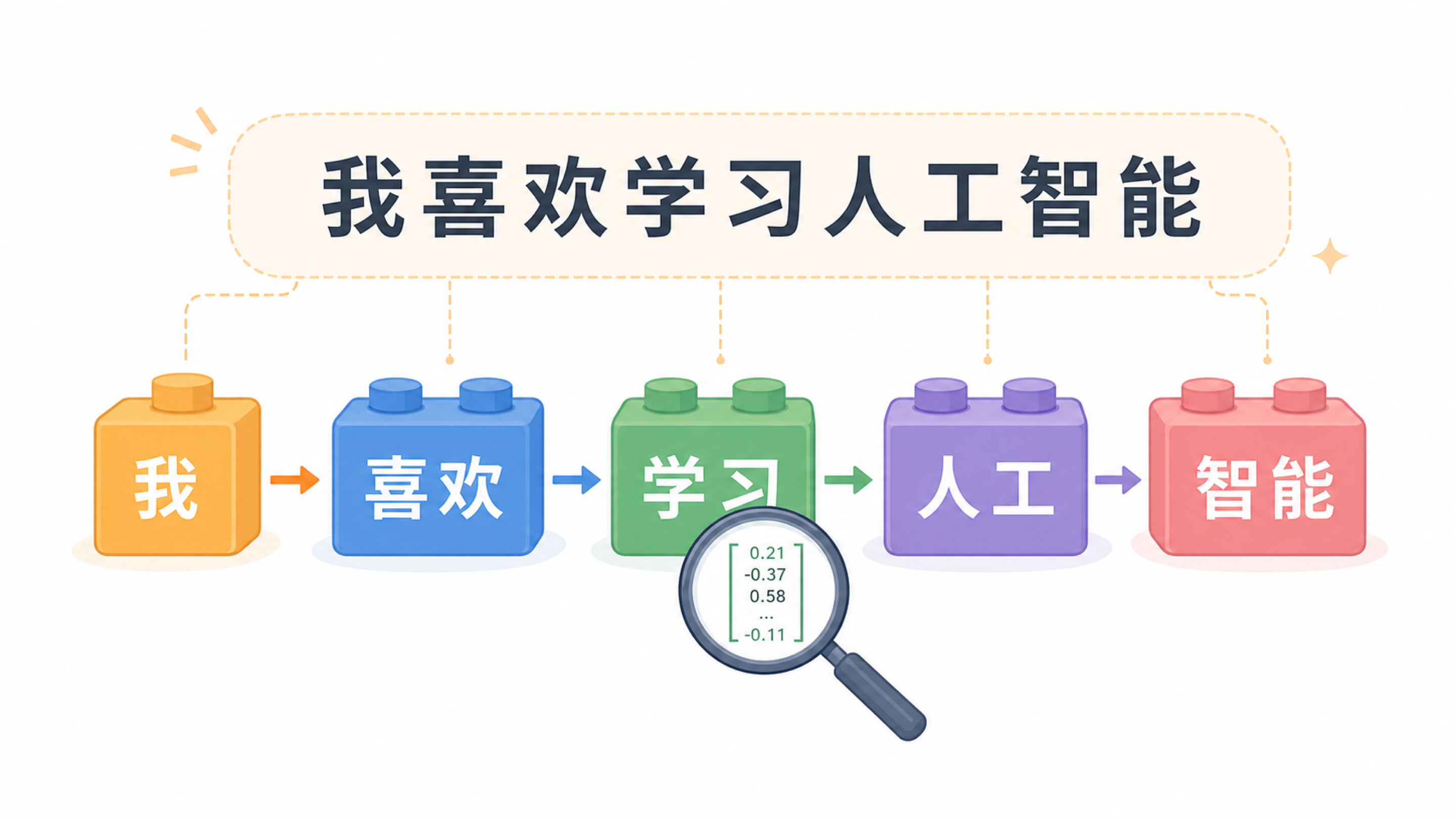
比如“我喜欢 Apple,也喜欢学习 LLM!”这句话,在真实模型里不一定按人类词语切开。中文可能按字或词片段,英文可能按单词或词根,标点也可能单独成为 token。不同模型使用的 tokenizer 不同,所以切法不完全一样。
概念拆解
Token 的作用,是把自然语言转换成模型可以计算的序列。模型并不是直接理解纸面上的文字,而是把文字映射成数字,再在这些数字之间学习关系。Token 是这个转换过程的基本单位。
为什么不直接按字或按词处理?因为语言非常复杂。中文没有天然空格,英文有词形变化,代码里有符号和缩进,表格里有大量重复结构。如果只按“字”切,序列可能太长;如果只按“词”切,遇到新词、缩写、代码标识符就很麻烦。Token 是一种折中:既能覆盖常见片段,也能拆开陌生内容。
Token 还直接影响成本。很多 API 会按输入 token 和输出 token 计费。你发给模型的系统指令、历史对话、资料、问题都算输入;模型生成的回答算输出。输入越长、输出越长,成本越高。
互动理解
你可以在下面输入不同文字,观察教学版拆分结果。它不等于真实 tokenizer,但能帮助你建立“模型会先切块”的直觉。
Token 拆分器
输入一段文字,观察它如何被拆成模型更容易处理的小块。
1. 原始句子
我喜欢 Apple,也喜欢学习 LLM!
2. 教学拆分
我 / 喜 / 欢 / Apple / , / 也 / 喜 / 欢 / 学 / 习 / LLM / !
3. 模型处理
12 个可见小块会一起进入上下文窗口
这只是教学拆分,不等同于真实模型 tokenizer;它用来帮助你建立“模型不是按完整句子理解,而是按小块处理”的直觉。
常见误区
第一个误区是把 token 等同于汉字数或单词数。实际切分和模型有关,不能简单用“多少字”等价估算。尤其是中英混排、代码、表格、特殊符号,token 数可能和直觉差很多。
第二个误区是只关注输入,忽略输出。让模型“详细解释”可能会产生大量输出 token;让它“给出 10 个方案并逐一分析”,成本和延迟都会增加。
第三个误区是以为压缩文字一定会提升效果。删掉无关内容有帮助,但把关键约束删掉,模型反而更容易误解任务。省 token 的目标不是越短越好,而是留下真正有用的上下文。
实用方法
日常使用大模型时,可以用三个习惯管理 token。
第一,把背景材料和当前问题分清楚,不要把一整堆无关材料都塞进去。第二,让模型先输出结构,再逐段展开,而不是一次要求写出所有细节。第三,长文处理时先摘要、分段、提取关键约束,再进入最终生成。
理解 token 后,你会发现“问得清楚”不只是表达能力,也是一种成本管理能力。好的输入不是最长,而是让每个 token 都为任务服务。
自我检查
可以试着比较三种输入:“帮我总结”“请总结下面这篇文章”“请用 5 条要点总结下面这篇文章,并标出每条依据”。第一种短,但模型要猜;第二种材料足,但输出标准不清;第三种虽然 token 更多,却更容易得到可检查结果。
所以管理 token 不是单纯追求短。真正好的输入,是把无关内容删掉,把关键目标、约束和材料留下。对于长文任务,先问“哪些内容必须进入模型视野”,比直接复制全文更重要。
真实场景
如果你要让模型阅读 20 页会议记录,不一定要一次全塞进去。可以先让它按时间线提取议题,再针对某个议题深入总结。这样每一轮的 token 都集中在当前目标上,模型更不容易混淆,也更便宜。
延伸阅读
- Token 数量直接影响上下文窗口能放多少内容——第 6 章:上下文窗口
- Token 也是计费的基本单位,理解成本结构请看第 7 章:Token 账本
一句话总结
Token 是大模型眼里的文字积木;输入、输出、上下文和费用,最终都绕不开 token。