核心问题
大模型为什么需要 RAG?如果模型已经读过很多资料,为什么还要临时检索文档?原因很简单:模型预训练学到的是过去大量文本中的模式,它不天然知道你公司的最新制度、你上传的合同、昨天更新的产品文档,也不能保证每个事实都记得准确。
RAG 的目标不是让模型“变成搜索引擎”,而是给它一场开卷考试:先把相关资料找出来,再让模型基于这些资料回答。
先建立直觉
闭卷考试靠记忆,开卷考试可以翻书。但开卷不代表一定满分。你还要找到正确页码,读懂题目,选出相关段落,并把答案组织清楚。翻错书、选错段落、理解错原文,仍然会答错。
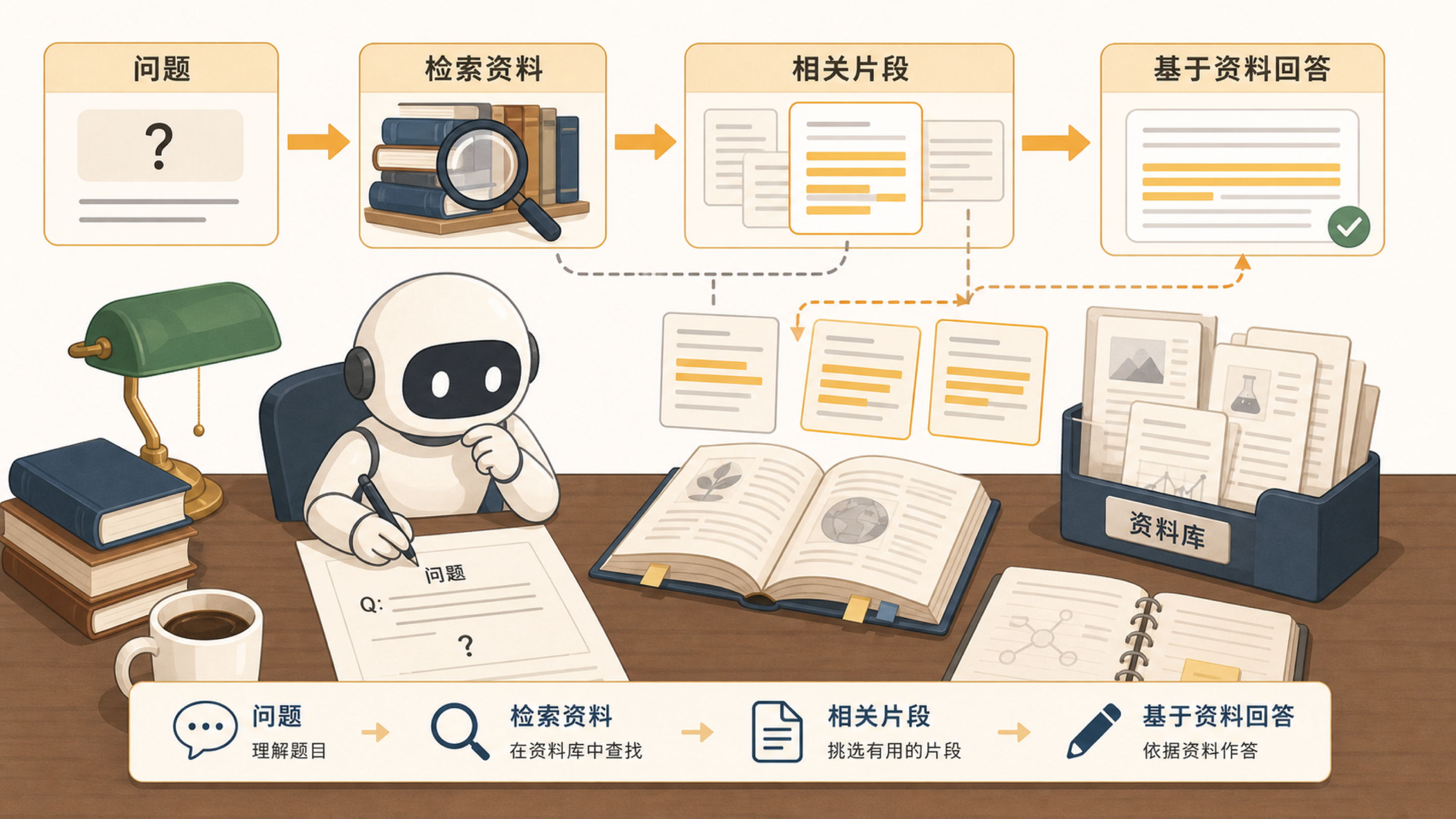
大模型回答企业内部问题时也是这样。你问“请假需要提前几天申请”,模型如果只靠记忆,可能给出通用答案;如果系统先检索公司制度,再把相关片段交给模型,答案就更可能贴近真实流程。
概念拆解
RAG 是 Retrieval-Augmented Generation,意思是检索增强生成。它通常包含五步。
第一,用户提出问题。第二,系统把问题转换成检索请求,在知识库中寻找相关文档或片段。第三,系统筛选出最可能有用的资料。第四,把这些资料和用户问题一起放进上下文窗口。第五,模型基于资料生成回答,并尽量说明依据。
这里有两个角色:检索系统负责“找资料”,大模型负责“读资料并组织答案”。如果检索系统找错了,大模型可能认真地基于错误资料回答;如果资料太长、太乱或互相冲突,模型也可能误解。
互动理解
下面的模拟器展示了 RAG 从用户问题到带依据回答的基本管线。重点看:RAG 多了一步“资料进入上下文”,而不是模型凭空记住所有信息。
开卷考试模拟器
切换是否提供资料,比较模型靠记忆回答和带依据回答的区别。
1. 用户问题
请假需要提前几天申请?
2. 检索资料
从企业知识库找制度片段。
3. 挑选片段
选择与请假流程最相关的原文。
4. 生成回答
把资料转成自然语言答案。
5. 标出依据
提醒用户回到原文确认适用范围。
企业知识库
根据 2026 年内部门户说明,请假需提前 2 天提交申请,直属主管审批后同步到考勤系统。
回答
根据提供的内部说明,请假需要提前 2 天在系统提交申请,并等待直属主管审批。仍建议点击原文确认适用范围。
常见误区
第一个误区是认为 RAG 可以消灭幻觉。RAG 能显著降低无依据回答的概率,但不能保证绝对正确。检索质量、文档质量、切片方式、排序策略和模型阅读能力都会影响结果。
第二个误区是把整份资料都塞进去。资料越多不一定越好。无关片段会占用上下文窗口,增加成本,还可能干扰模型。
第三个误区是忽略来源展示。没有引用、没有原文片段、没有可回查链接的 RAG,很难让用户判断答案是否真的有依据。
实用方法
设计或使用 RAG 时,可以关注四件事。
第一,知识库是否可靠、更新及时。第二,检索出来的片段是否真的和问题相关。第三,回答是否能标出依据,而不是只给结论。第四,高风险场景是否有人类复核流程。
普通用户也可以借鉴 RAG 思路:不要只问“这份合同有什么风险”,而是先提供合同原文,再要求模型“只基于原文回答,无法判断的地方标注不确定”。这比让模型凭印象回答可靠得多。
自我检查
可以用“公司制度问答”检验 RAG 是否真的可靠。问一个你知道答案的问题,看系统能否找出正确制度片段;再问一个制度里没有的问题,看它会不会坦白没有依据。如果两个都做不到,说明系统可能只是把 RAG 当包装词。
好的 RAG 答案应该让你看到三件事:答案是什么、依据在哪里、哪些地方仍然不确定。缺少其中任何一项,都不适合直接用于高风险决策。
真实场景
企业知识库问答常见失败,是检索到了旧制度。比如 2024 年的报销政策和 2026 年的新政策同时存在,如果系统没有时间过滤,模型可能引用旧文档回答。此时问题不在模型文笔,而在检索和文档治理。
所以 RAG 项目不只是接一个向量库。文档版本、权限、过期标记、引用展示、人工反馈,都决定它能不能真正用于业务。
如果把 RAG 用在客服场景,还要注意回答口径。模型找到原文后,仍可能把内部措辞直接发给客户,造成误解。好的系统会把“内部依据”和“对外表达”分开处理,先保证依据正确,再转换成合适的用户语言。
这一步很容易被忽略。
延伸阅读
- RAG 是应对幻觉的重要手段,先理解幻觉的成因和风险——第 12 章:幻觉
- RAG 的"找资料"依赖 Embedding 做语义检索——第 14 章:Embedding解释机器怎样按意思找资料
一句话总结
RAG 是给模型开卷资料,而不是赋予它绝对事实能力;资料找得准、读得对、能回查,才是真正可靠的关键。