核心问题
为什么 GPT 这类生成式路线会突然改变很多人的工作方式?在它之前,AI 已经能识别图片、推荐商品、翻译句子、做搜索排序,但普通人很少觉得自己每天都在和 AI 协作。GPT 路线的变化在于:它把“生成下一个文字块”这件事扩展成了对话、写作、总结、代码、计划和解释。
这一章不是要说 GPT 路线打败了所有其他路线,而是理解它为什么特别适合成为普通人的通用入口。
先建立直觉
早期很多语言模型更像阅读理解考生:给它一段话,让它判断类别、找出答案、填补空缺。它很有用,但交互方式比较窄。你要先把任务改造成它能处理的格式,它再给你一个结果。
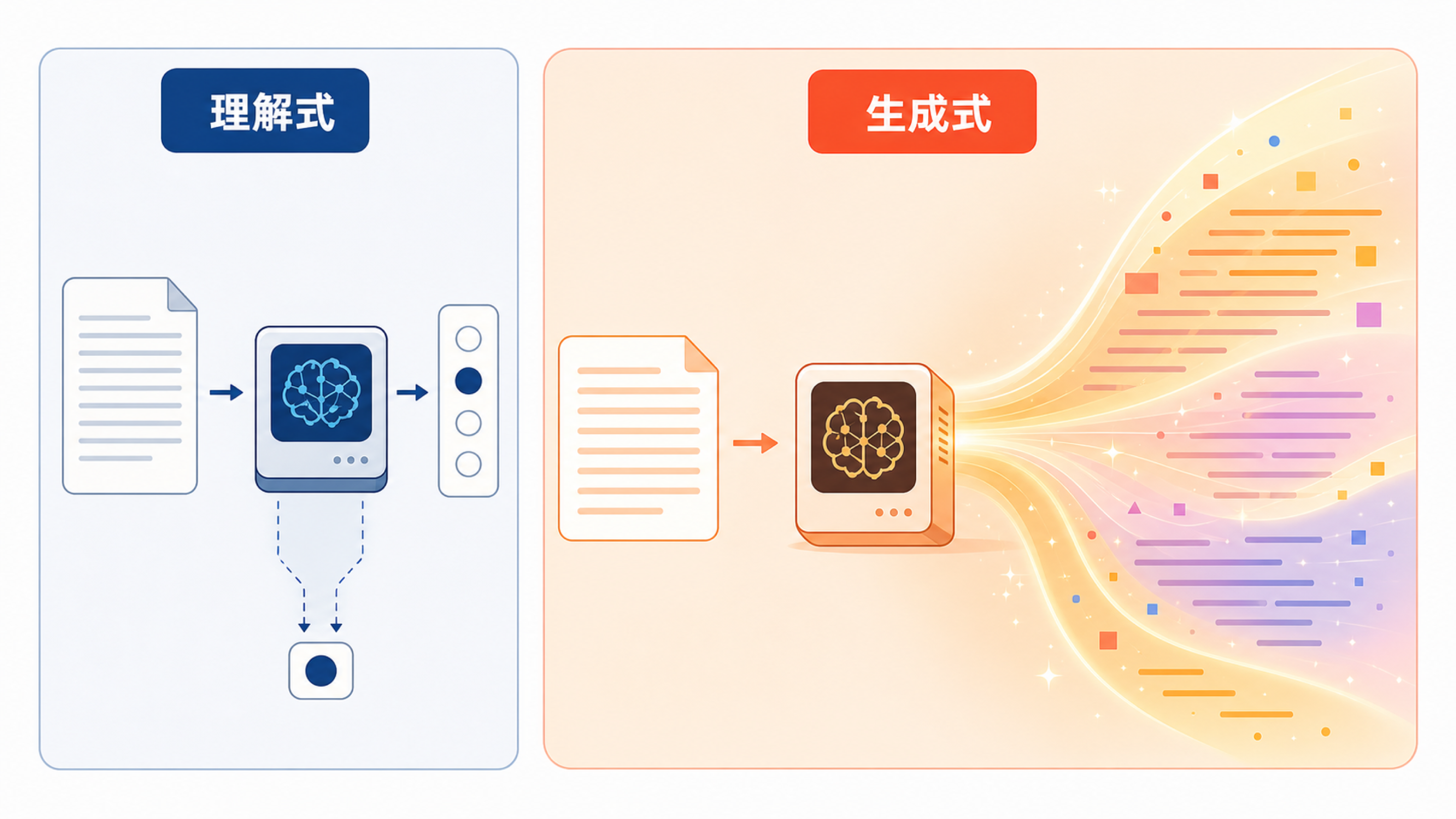
GPT 路线更像接龙写作者。你给它一句开头,它预测后面最可能出现什么;再把新生成的内容接回上下文,继续预测下一段。这个看似简单的机制,一旦模型足够大、训练数据足够多,就可以表现出写邮件、改文案、解释概念、生成代码、模拟对话等能力。
它的强大之处不是“会聊天”本身,而是很多任务都可以转化成“在当前上下文中继续生成最合适的文本”。
概念拆解
GPT 中的 G 是 Generative,强调生成;P 是 Pre-trained,强调先在大规模文本上预训练;T 是 Transformer,是支撑现代大模型的重要网络结构。
生成式路线的核心是自回归生成:模型先看已有上下文,预测下一个 token;生成出来的 token 又成为新的上下文,再预测下一个。一步步接下去,就形成完整回答。
这种路线天然适合开放式任务。用户不必把问题压缩成固定选项,可以直接说“帮我解释一下”“把这段改得更清楚”“列出方案并比较优缺点”。模型通过续写,把任务转换成文本输出。
但这也带来风险。模型的目标是生成合理文本,不是天然保证事实正确。它能把话说得顺,不代表每句话都经过外部验证。
互动理解
下面的对比组件展示了理解式路线和生成式路线的差异。重点看它们不是胜负关系,而是任务入口不同。
理解式路线 vs 生成式路线
这不是胜负表,而是看两种路线分别擅长什么。
更像接龙写作和对话续写
今天天气很好,我和朋友去公园散步,还顺路买了咖啡。
它只看已经出现的内容,然后不断生成下一个文字块,所以更容易扩展成开放对话。
常见误区
第一个误区是把 GPT 路线理解成“真正懂了”。它的表现很像理解,因为它能根据上下文生成恰当回答;但在事实、计算、最新信息和高风险判断上,它仍可能出错。
第二个误区是认为生成式路线适合所有问题。分类、搜索排序、实时控制、严格数据库查询等任务,未必都应该交给大模型直接生成。很多系统会把大模型和传统程序、数据库、检索系统、审核流程组合起来。
第三个误区是只看模型本身。一个好用的 AI 产品,往往不只是一个模型,还包括提示词设计、上下文管理、工具调用、权限控制、日志和人类复核机制。
实用方法
当你判断一个任务是否适合 GPT 路线时,可以看它是否主要产出语言或结构化文本。如果任务是解释、总结、写作、改写、比较方案、生成草稿,大模型通常很有价值。如果任务要求实时事实、精确计算、强合规责任或不可逆操作,就需要配合工具、数据库和人工审核。
GPT 路线改变世界,是因为它把 AI 的交互门槛降得很低:普通人可以用自然语言直接表达需求。但越容易使用,越要清楚它不是事实机器,而是一个强大的文本生成和协作接口。
自我检查
遇到一个任务时,可以先判断它是不是“语言接口友好”。如果你要写一封邮件、解释一个概念、把会议记录整理成待办,大模型很合适;如果你要查询账户余额、更新库存、发送正式通知,就不能只靠生成文本,还必须连接真实系统并设置权限。
GPT 路线的真正价值,是把很多工作变成了“先生成一个可修改的草稿”。草稿可以快,但最终版本要经过事实核对和人类判断。把它当成草稿机,你会得到效率;把它当成真理机,就容易出错。
真实场景
比如准备一场分享。你可以让大模型先把主题拆成大纲,再生成开场白、案例和结尾。这个过程非常适合生成式路线,因为产物就是语言。但演讲中的数据、客户案例、公司政策,不能让模型凭空补。你应该把真实材料提供给它,或者在生成后逐条核对。GPT 路线帮你加速表达,不替你承担事实责任。
这也是后面 RAG、工具调用和 Workflow 会出现的原因:生成式模型负责组织语言,但真实资料、实时状态和最终审核要由系统和人共同补上。
延伸阅读
- 回顾本单元的核心线索和关键收获 → 第一单元总结
- GPT 路线的核心机制"预测下一个词"会在第 8 章:接下一句话详细展开
- 深度学习如何逐层提取特征是第 3 章:深度学习的核心内容
一句话总结
GPT 路线的力量在于把许多任务转化成上下文中的连续生成,但生成得像真的,不等于每句话都是真的。