核心问题
传统机器学习常常需要人先告诉机器“看哪些特征”。比如识别房价时看面积、地段、楼层;识别垃圾邮件时看标题、链接、发件人。可是在图片、语音、自然语言这类复杂任务里,人很难把所有有效特征提前写清楚。猫的轮廓、语气的变化、句子的含义,都不是几条简单规则能描述完的。
深度学习的突破就在这里:它让模型可以从数据中逐层提取特征,而不是完全依赖人类手工设计特征。
先建立直觉
想象你教一个孩子认猫。你不会先写一本几百页的规则书,告诉他“耳朵角度必须在多少度之间,胡须长度如何计算,眼睛和鼻子的距离是多少”。你更可能给他看很多猫的照片:站着的、趴着的、黑色的、白色的、卡通的、真实的。看多之后,孩子会逐渐抓住“猫感”。
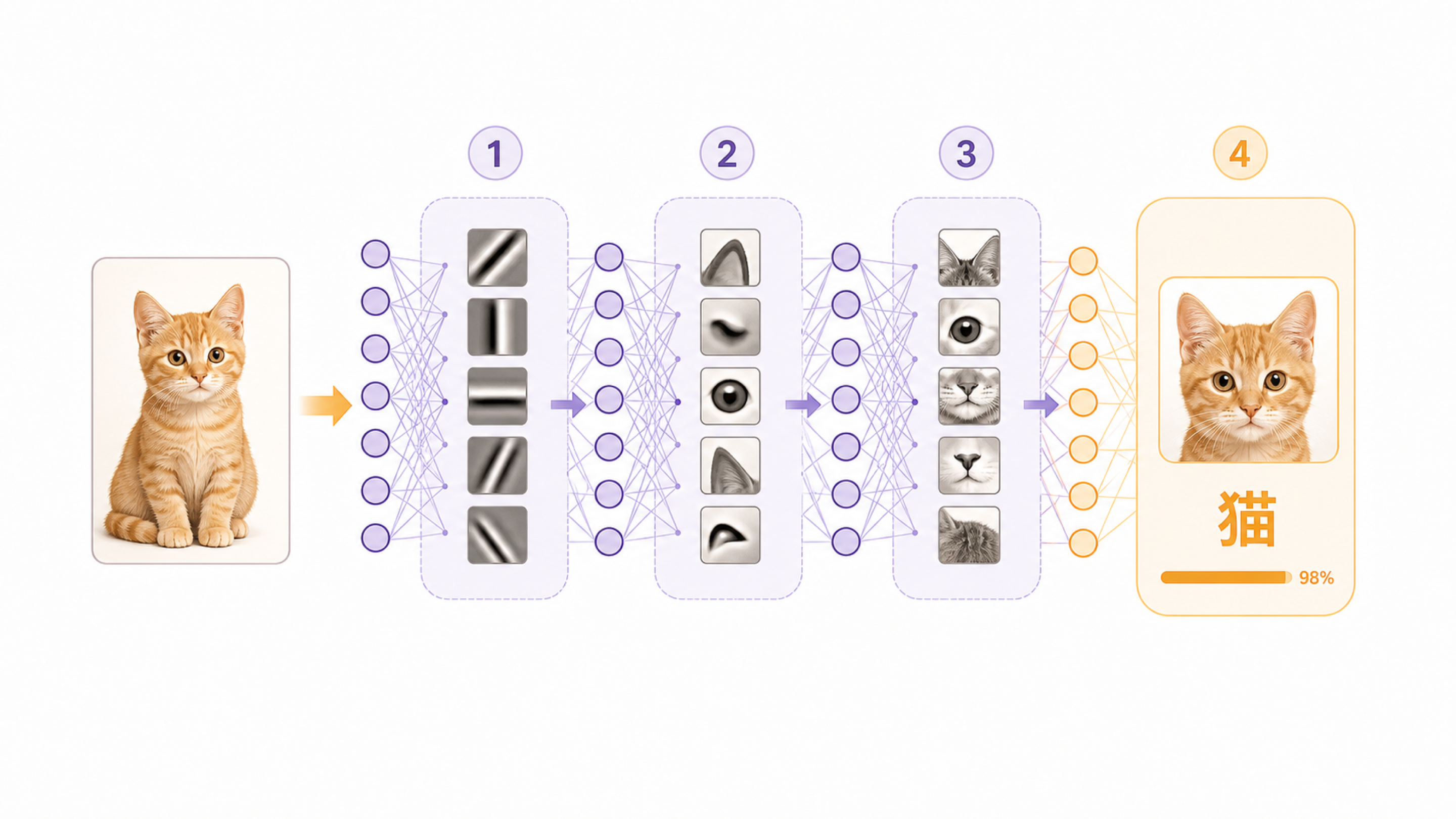
深度学习也类似。它不会只看单一线索,而是在多层网络中逐步组合线索。浅层可能关注边缘、颜色、局部纹理;中间层开始组合出耳朵、眼睛、胡须;更深层再把这些线索合起来,判断这张图是不是猫。
这种“逐层提取”的能力,让深度学习特别适合处理复杂、模糊、难以手写规则的数据。
概念拆解
深度学习里的“深度”,主要指神经网络有很多层。每一层都不是孤立判断,而是把上一层的结果继续加工。前面几层学习简单线索,后面几层学习更抽象的组合。
以图片识别为例,第一层可能只知道哪里有边缘,第二层把边缘组合成形状,第三层把形状组合成物体部件,最后几层再判断整体类别。语言模型虽然处理的是文字,但思路相似:它会从字词、短语、句法、语义关系中逐步形成更复杂的表示。
这也是为什么深度学习需要大量数据和计算资源。层数越多、参数越多,模型可以表达的模式越复杂,但训练成本、调试难度和出错的不透明性也会增加。
互动理解
下面的组件用猫的识别过程模拟“特征提取”。你可以点击不同线索,观察模型如何把零散特征组合成判断。
特征探测器
点击线索,体会深度学习为什么不只依赖人手写的规则。
图片中的动物
置信度 40%
常见误区
第一个误区是以为深度学习会像人一样“理解”特征。它确实能从数据里提取有效模式,但这些模式并不总等于人类可解释的概念。有时模型可能依赖背景、颜色、水印等无关线索做判断。
第二个误区是以为层数越深越好。更大的网络有更强表达能力,但也更依赖数据、算力和训练技巧。小任务用过大的模型,可能成本高、速度慢,还不一定更可靠。
第三个误区是忽略数据偏差。如果训练图片里的猫总在沙发上,模型可能把沙发也当成判断线索。到了真实世界,换个背景就可能出错。
实用方法
理解深度学习时,记住三个判断点。
第一,它适合处理特征很难手写的任务,例如图像、语音、自然语言。第二,它的效果依赖大量高质量数据,不是随便给一点样本就能自动变强。第三,它的内部判断不总是透明,所以关键场景需要测试、解释和人类复核。
大模型之所以能理解和生成语言,正是深度学习能力在更大规模上的延伸。它不是突然出现的魔法,而是从“模型自己找特征”这条路线一路发展出来的结果。
自我检查
可以用“识别猫”和“识别投诉邮件”对比理解深度学习。识别猫时,模型要从像素中找边缘、纹理和形状;识别投诉邮件时,模型要从词语、语气和句子关系中找情绪和意图。两者输入不同,但都需要从低层线索组合出高层判断。
如果一个任务可以轻松写成几条规则,深度学习未必是必要方案。比如“金额超过 5000 元就需要主管审批”,规则程序更简单、更透明。深度学习真正擅长的是那些规则难写、样本很多、模式复杂的任务。理解这一点,可以避免把所有自动化问题都交给大模型。
真实场景
客服质检就是一个典型例子。你很难手写规则判断一段对话是否“态度冷淡”或“没有解决问题”,因为表达方式太多。深度学习模型可以从大量对话样本中学习语气、上下文和结果之间的关系。但如果公司只用某个地区、某个团队的数据训练,换到别的业务线就可能不准。这时需要持续抽样复核,而不是一次训练后永久使用。
如果把它放到大模型语境里,原理也是一样:模型能从大量文本中提取表达、语义和任务结构,但它仍然依赖训练数据和评估方法。深度学习解决了“特征难写”的问题,却没有消除“数据是否代表真实场景”的问题。
所以深度学习既是能力来源,也是评估责任的开始。
越自动,越要评估。
延伸阅读
- 深度学习的"从数据里自己找特征"是第 2 章机器学习思路的延续——回顾第 2 章:机器学习
- 深度学习走到大规模就是大模型,GPT 路线是其中最受关注的一支——第 4 章:为什么 GPT 路线改变了世界
一句话总结
深度学习的关键价值,是让模型从大量数据中逐层提取复杂特征,而不是完全依赖人类提前写好规则。