核心问题
机器学习最容易被误解成“机器自己突然懂了”。事实上,它并不是凭空产生经验,而是从大量例子里找出可重复的线索。你给它看的例子越代表真实世界,它越可能学到有用规律;例子越偏、越少、越乱,它学到的东西就越可能不可靠。
这一章要解决的问题是:机器到底怎样从例子里学经验?它和传统程序最大的区别是什么?为什么同样是“自动判断”,有些系统需要人写规则,有些系统却可以从数据里学出规则?
先建立直觉
想象你要教一个新同事分辨垃圾邮件。传统做法像写一本厚厚的规则手册:标题里有“中奖”就扣分,正文里有陌生链接就扣分,发件人域名奇怪就扣分。规则越多,维护越麻烦,而且很容易被新花样绕过。
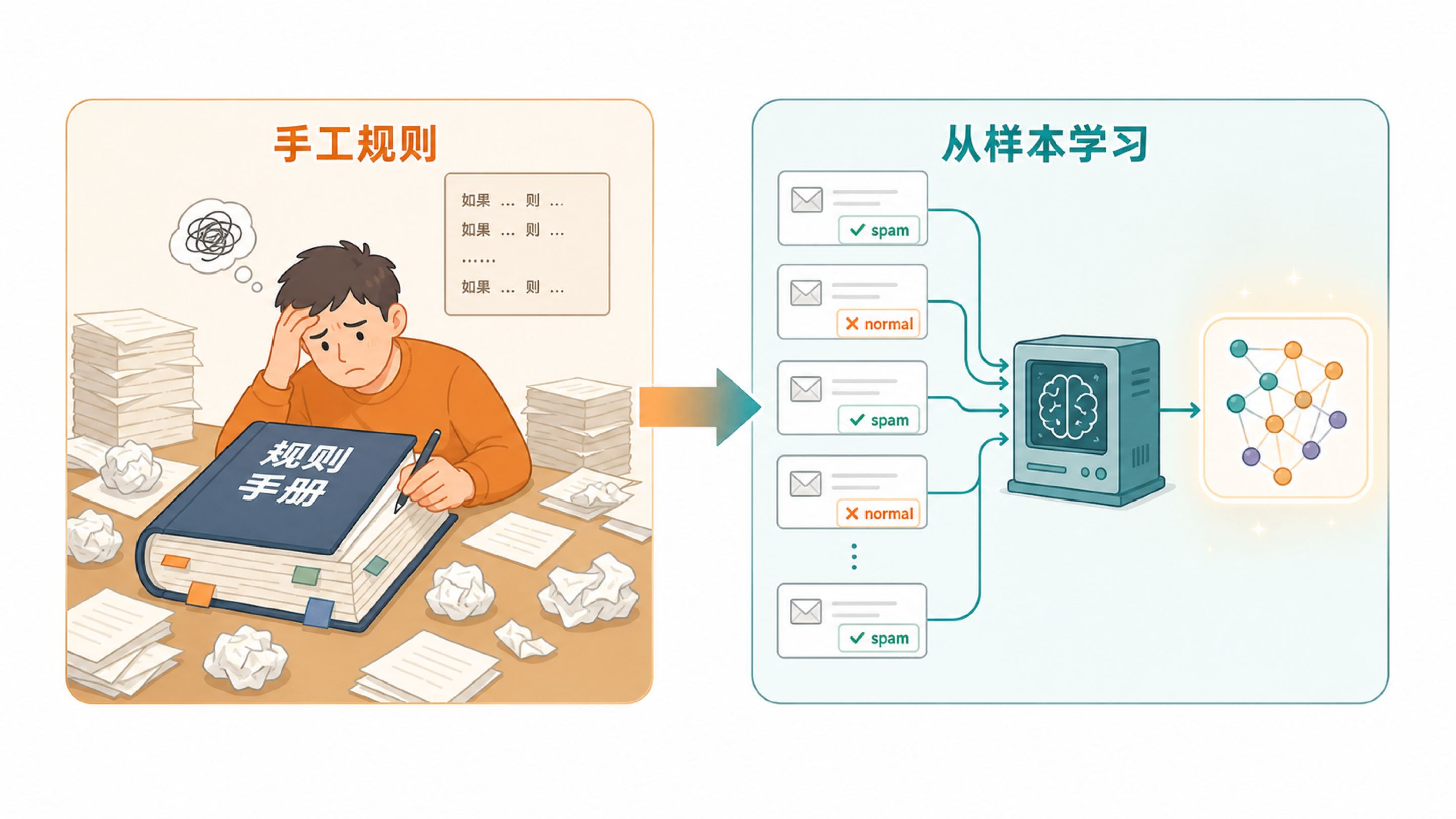
机器学习的做法更像让同事看大量历史邮件:这些是垃圾邮件,那些是正常邮件。看得足够多以后,他会发现一些线索经常同时出现,比如夸张标题、紧迫语气、异常链接、陌生发件人。你没有逐条告诉他所有规则,但他从例子里归纳出了判断经验。
这并不表示机器有常识。它学到的是“在训练样本中,哪些特征和哪些标签经常一起出现”。这点很重要,因为它解释了机器学习为什么有用,也解释了它为什么会受数据质量影响。
概念拆解
一个最小的机器学习过程通常包含三件事:样本、标签和模型。
样本是给机器看的例子,例如一封封邮件、一张张图片、一条条历史订单。标签是人类或系统给出的答案,例如“垃圾邮件/正常邮件”“猫/狗”“会流失/不会流失”。模型则负责在样本和标签之间寻找规律。
训练时,模型会先做预测,再和正确标签比较。如果预测错了,就调整内部参数;如果预测对了,就强化当前方向。这个过程重复很多次,模型就逐渐学会在新样本上做判断。
机器学习和手写规则的关键差别在于:规则程序的判断逻辑主要由人直接写出;机器学习模型的判断逻辑主要从数据中学习。人仍然很重要,但人的工作从“写所有规则”变成了“准备数据、定义目标、评估结果、处理错误”。
互动理解
下面的小组件会逐步展示训练样本。注意看样本增加后,机器并不是记住某一封邮件,而是在归纳“哪些线索更像垃圾邮件”。
从例子里学规律
逐条揭示训练样本,观察机器学习和手写规则的区别。
标题含“限时中奖”,发件人陌生
垃圾邮件
机器正在归纳
初始假设
只看到一个垃圾样本,机器只能形成很粗的猜测。
当前规则:标题像促销、来源陌生时,需要提高警惕,但证据还不稳。
常见误区
第一个误区是以为样本越多一定越好。数量当然重要,但质量更重要。如果训练数据里充满错误标签,模型会认真学习错误经验。就像让新人只看错题答案,他会越学越偏。
第二个误区是以为模型学到的规律永远有效。现实世界会变化,诈骗邮件会换话术,用户习惯会改变,市场环境会波动。过去的数据能帮助预测未来,但不能保证未来完全重复过去。
第三个误区是把相关性当因果。模型可能发现“某类词经常出现在垃圾邮件里”,但这不等于这些词本身导致邮件有害。机器学习很擅长找关联,却不一定理解背后的原因。
实用方法
判断一个机器学习系统是否可靠,可以问四个问题。
第一,它看过的例子是否足够接近真实使用场景?第二,标签是否准确,还是混入了大量错误判断?第三,它犯错时有没有人复核,尤其是在医疗、法律、投资等高风险场景?第四,环境变化后有没有重新评估,而不是长期沿用旧模型?
普通人不需要掌握算法公式,但要记住:机器学习的能力来自例子,边界也来自例子。没有见过、见得太少、见得太偏的情况,都是它容易出错的地方。
自我检查
可以拿身边的推荐系统做练习。短视频平台给你推荐内容时,它不是先理解你这个人,而是从你点击、停留、点赞、跳过等例子里学习偏好。你过去经常看某类内容,它就更可能继续推荐类似内容。
这也解释了推荐系统为什么会形成信息茧房:如果训练反馈只来自你的历史行为,模型就会越来越确信你只喜欢那一类内容。机器学习在这里没有道德判断,它只是优化被定义好的目标。所以使用任何机器学习系统,都要同时看“学了什么”和“被奖励了什么”。
真实场景
在公司里,如果你想用机器学习预测客户是否会流失,不能只把“最近没登录”这一个规则写进去。更好的做法是收集历史客户行为:登录频率、工单数量、续费记录、使用功能、是否参加培训,再标出哪些客户后来真的流失。模型从这些例子里学到风险线索,但业务人员仍要检查它有没有误伤新客户或低频高价值客户。
这类检查决定了模型能不能真正进入流程。
延伸阅读
- 如果不确定 AI 和机器学习的层级关系,可以回顾第 1 章:AI 到底是什么
- 机器学习只看手工特征,深度学习让机器自己找特征——第 3 章:深度学习会讲这个飞跃
一句话总结
机器学习不是机器凭空变聪明,而是从大量带答案的例子里归纳规律;例子的质量决定了经验的质量。