核心问题
很多人第一次接触 AI,会把它直接等同于 ChatGPT、机器人,或者某个会画图、会写文案的产品。这样理解很自然,因为我们通常是从一个具体工具认识一项技术。但如果只记住产品名字,就很容易在后面混淆:机器学习、深度学习、大模型到底是不是一回事?为什么有些 AI 能识别垃圾邮件,有些能推荐路线,有些能聊天写文章?
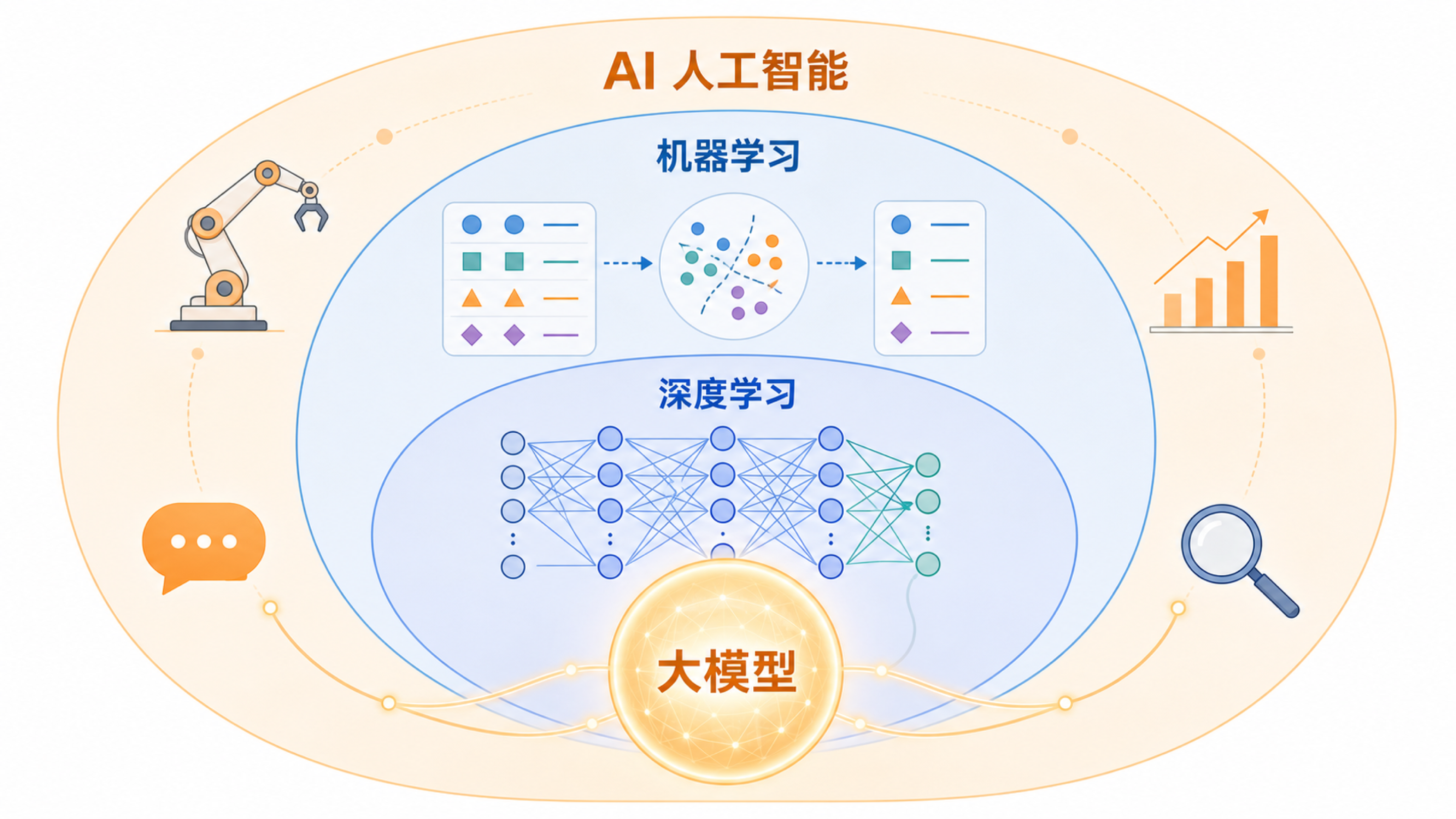
更准确的说法是:AI 不是某一个软件,而是一类目标。只要我们希望机器完成过去需要人类判断、识别、表达、规划或决策的任务,就进入了 AI 的范围。大模型只是今天最受关注、最容易被普通人感知的一类 AI 系统。
先建立直觉
可以把 AI 想成一个很大的“智能工具箱”。工具箱里有很多工具:有的负责识别图片,有的负责预测价格,有的负责推荐视频,有的负责理解和生成文字。你不会因为家里最常用的是螺丝刀,就说整个工具箱等于螺丝刀;同样,也不能因为今天最常用的是 ChatGPT,就说 AI 等于聊天机器人。
再换一个生活场景:商场里的自动扶梯、门口的人脸闸机、外卖平台的配送预估、邮箱里的垃圾邮件过滤,都可以包含 AI 能力。但它们背后的技术路线不完全一样。有些系统靠人工规则,有些靠机器学习,有些靠深度学习;大模型则是在深度学习基础上,把数据规模、参数规模和任务范围都推到了更大的层级。
概念拆解
AI、机器学习、深度学习、大模型之间不是并列关系,而是层层包含的关系。
- AI 是总目标:让机器表现出某种智能能力。
- 机器学习 是实现 AI 的一种主流方法:不是把所有规则写死,而是让机器从大量例子中归纳规律。
- 深度学习 是机器学习中的一种强力方法:用多层神经网络处理图像、语音、语言等复杂数据。
- 大模型 是深度学习在海量数据和巨大参数规模上的结果,尤其擅长处理语言、图像、代码和多步骤任务。
这几个词的关系很像“交通工具、汽车、电动车、某款智能电动车”。交通工具范围最大,汽车是其中一类,电动车又是汽车中的一类,而某款智能电动车只是一个具体产品。产品可以很强,但不能反过来代表整个类别。
AI 的发展不是一夜之间发生的。从最早的手写规则,到机器学习从样本中归纳,再到深度学习自己找特征,最后到大模型统一处理多种任务,每一步都建立在前面基础之上。下面的时间线把这个演进过程串了起来。
AI 发展时间线
规则时代
人把规则逐条写进程序,机器严格按规则执行。能处理固定任务,但场景一变就要重写所有规则。
Eliza 聊天程序用模式匹配模拟心理医生;专家系统把几百条 if-then 规则编进知识库诊断故障。
统计机器学习
机器不再只靠手写规则,而是从大量带标签的样本中归纳规律。数据和标签的质量,决定了学到经验的质量。
垃圾邮件过滤器从历史邮件中学习'哪些特征更像垃圾';推荐系统从点击和停留行为中预测你的偏好。
深度学习突破
多层神经网络让机器从数据中逐层提取特征,不再依赖人类手工设计每个判断维度。
图像识别从边缘→形状→部件→整体逐层抽象;AlphaGo 从棋谱中自学策略击败世界冠军李世石。
Transformer 架构
自注意力机制让模型能并行处理长文本中任意两个词之间的关系,解决了传统 RNN 长距离依赖丢失和无法并行训练的问题,成为现代大模型的技术底座。
Google 论文《Attention Is All You Need》发表,此后 GPT、BERT、Claude 等主流模型全部基于 Transformer。
大模型崛起
GPT-1 → GPT-2 → GPT-3 → ChatGPT,参数从亿级膨胀到千亿级。模型不再只是续写工具,开始展现对话、推理、编程等通用能力。
ChatGPT 2022 年底发布,两个月突破 1 亿用户,让全球普通人第一次切身感受到'AI 能跟我聊天、帮我做事'。
Agent 与多模态
大模型从只会聊天,扩展到调用工具、理解图片和音频、自主执行多步骤任务。AI 开始从'会说'走向'能做'。
多模态模型能直接看懂截图和 PDF 文档;Agent 可以搜索→计算→发邮件形成工作闭环;开源小模型让手机和浏览器也能本地运行 AI。
互动理解
下面的层级图可以帮助你把四个概念放回正确位置。点击不同圈层时,重点看”它属于谁”和”它解决什么问题”。
AI 层级地图
点击不同圈层,观察 AI、机器学习、深度学习和大模型的包含关系。
当前圈层:AI
让机器表现出类似智能的能力,是最大的一层愿景。
自动识别垃圾邮件、推荐路线、生成图片,都可以归入 AI。
当前圈层:机器学习
AI 的一种主流方法:不手写所有规则,而是让机器从例子里找规律。
给机器看很多房价样本,让它学习面积、位置和价格的关系。
当前圈层:深度学习
机器学习的一次升级,用多层神经网络从大量数据里提取特征。
不用手写“猫有胡须”,模型自己从图片里发现这些线索。
当前圈层:大模型
深度学习在语言、图像等领域扩展到大规模数据和参数后的结果。
读过海量文本后,可以根据上下文生成回答、总结和计划。
常见误区
第一个误区是把 AI 神秘化,好像它一定像人一样理解世界。其实很多 AI 系统只是把输入转换成输出:识别一张图片、判断一封邮件、预测下一步最可能发生什么。它可以非常有用,但不必等同于人类意识。
第二个误区是把大模型等同于所有 AI。大模型确实覆盖了写作、问答、总结、代码等很多任务,但地图导航、金融风控、工业质检、推荐系统中仍有大量并不以大语言模型为核心的 AI。
第三个误区是只看“像不像人”。普通人判断 AI 产品时,更应该问:它的输入是什么?输出是什么?输出能不能被验证?出错后谁负责?这些问题比“它是否真的聪明”更实用。
实用方法
以后遇到一个新 AI 产品,可以按三步判断它的位置。
第一步,看它解决什么任务:识别、预测、生成、规划,还是执行工具。第二步,看它主要依赖什么能力:规则、机器学习模型、深度学习模型,还是大模型。第三步,看它的错误后果:只是推荐错一首歌,还是会影响医疗、法律、财务决策。越高风险,越不能只因为它叫 AI 就相信它。
这样理解之后,你会发现 AI 不是一个魔法词,而是一组不同技术和应用的统称。大模型是进入 AI 世界的一扇门,但不是整栋房子。
自我检查
读完这一章,可以用三个小问题检验自己是否真的分清了层级。
看到一个“自动识别发票”的系统时,先不要急着说它是大模型。你可以问:它是不是只在识别固定格式?有没有从历史样本中学习?是否需要生成自然语言?如果它只是把票面字段抽出来,可能是 OCR、规则和机器学习组合;如果它还能解释报销制度、生成说明,才可能需要大模型参与。
看到一个“AI 写作助手”时,也不要只看产品名。它很可能以大模型为核心,但周围还会有模板、检索、审核、权限和存储。真正的产品能力,往往来自模型和应用系统的组合。
延伸阅读
- 如果你还没完全理解"机器怎样从例子中学习",建议继续读第 2 章:机器学习,它把这层关系展开了讲
- 想理解 AI 工具箱里最受关注的那件"工具"具体怎么工作,可以跳到第 4 章:为什么 GPT 路线改变了世界
一句话总结
AI 是让机器完成智能任务的大目标,机器学习和深度学习是实现路径,大模型只是今天最强、最常见的一类实现形态。