核心问题
大模型为什么只是“预测下一个词”,却能表现得像在理解、推理和写作?这个问题听起来反直觉:如果它只是在接下一句话,为什么能解释概念、写邮件、改代码、制定计划?
关键在于,“预测下一个 token”不是简单猜字游戏。当模型在海量文本中反复训练,它学到的是语言背后的模式:事实之间的关联、问题和答案的结构、故事发展的常识、代码语法、论证方式和人类表达习惯。
先建立直觉
想象你在看一句话:“小明没带伞,外面正在下雨,他走到门口……”你很自然会猜后面可能是“回去拿伞”,也可能是“犹豫了一下”。你不是只根据最后一个字猜,而是综合了前面所有上下文、生活经验和故事逻辑。
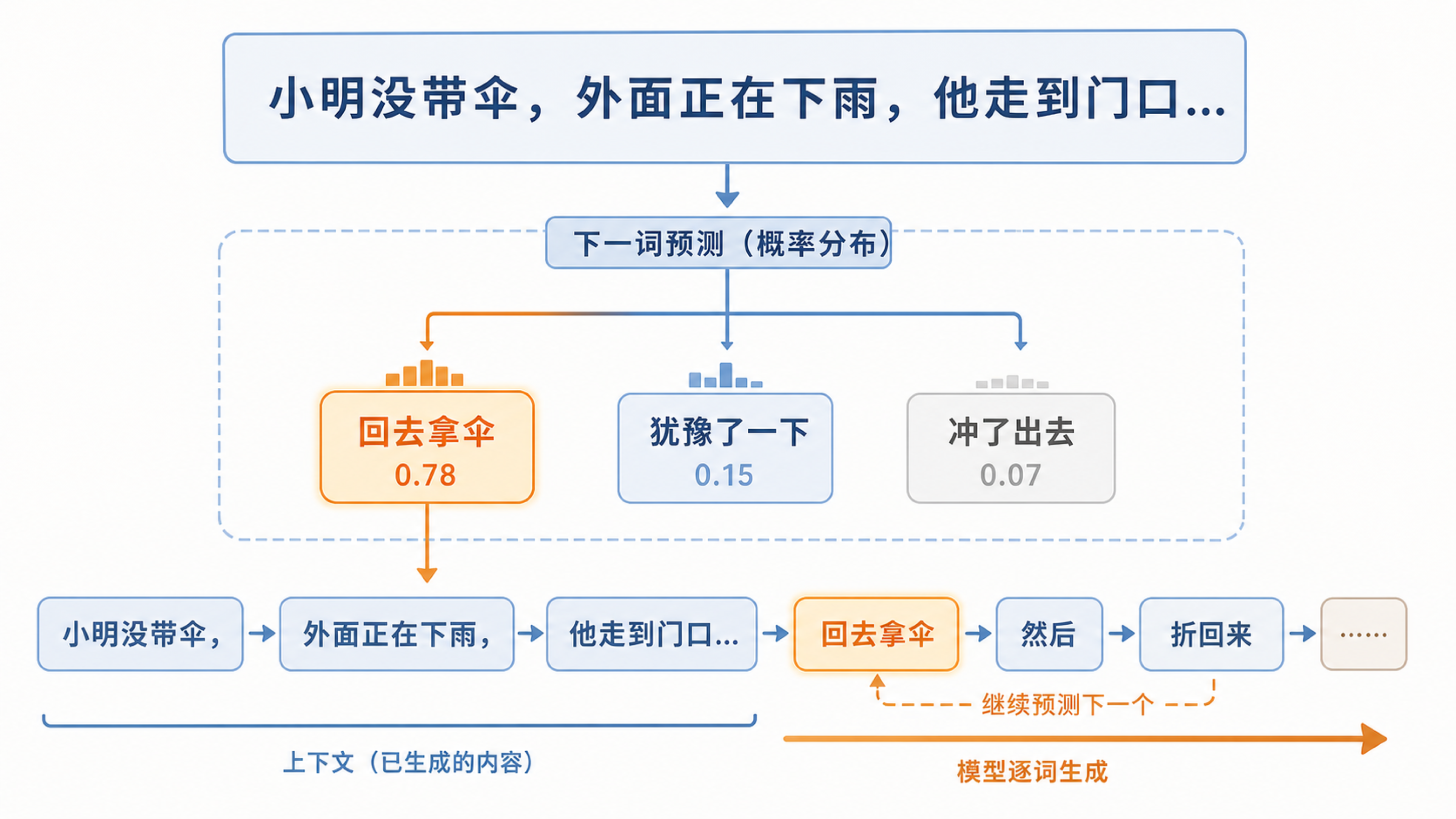
大模型做的事情类似,但规模大得多。它不是只看一个词,而是看上下文里的大量 token,再判断下一步哪些 token 更可能出现。一次预测只产生一小块,但持续很多次,就形成一句话、一段解释,甚至一篇文章。
概念拆解
训练时,模型看到大量文本,并不断练习“给定前文,预测后文”。如果预测错了,它会调整内部参数;如果预测接近真实文本,它会强化相关模式。经过巨大规模的训练,模型学会了很多隐含规律。
比如,看到“退货政策”时,它知道后面常常出现“期限、条件、凭证、退款方式”;看到“请比较两个方案”时,它知道答案通常包含维度、优缺点和建议;看到代码函数开头时,它知道后面应符合语法和上下文变量。
这就是为什么 next-token prediction 会涌现出类似理解的表现。它不是人类式理解,但在足够丰富的文本模式中,很多理解任务都可以转化为“生成合适的后续内容”。
互动理解
下面的小游戏展示了候选续写的概率。注意概率最高的选项通常最符合上下文,但低概率选项并非永远不会出现。
预测下一句话
模型生成时会不断判断:在当前上下文后面,哪个续写最可能。
小明没带伞,外面正在下雨,他走到门口……
当前选择:回去拿伞。概率高不代表永远正确,但它说明这句话和上下文最贴近。
常见误区
第一个误区是低估预测任务。很多人听到“预测下一个词”就觉得简单,但如果上下文是法律合同、代码仓库、医学摘要或复杂推理题,下一个 token 的合理性背后包含大量结构知识。
第二个误区是高估预测任务。预测得顺不等于事实被验证。模型可能生成一个看起来很像论文引用的句子,但引用本身并不存在。它学到的是文本模式,不是自动连接真实世界的数据库。
第三个误区是把模型输出看成固定答案。生成过程存在概率分布,同一个问题在不同设置下可能得到不同表达。这不是系统坏了,而是生成式模型的基本特性。
实用方法
用大模型时,可以把它当成“上下文续写能力很强的协作者”。你给的上下文越清楚,它越容易沿着正确方向续写。任务目标、背景、约束、示例、输出格式,都会改变后续生成。
如果你需要稳定答案,就给明确边界和检查要求。如果你需要创意,就允许更多候选方向。如果你需要事实可靠,就不要只依赖生成本身,而要加入资料来源、检索或人工核验。
理解“接下一句话”之后,你会更清楚 Prompt 的本质:不是咒语,而是在控制模型接下来应该沿着哪条轨道生成。
自我检查
可以拿同一个开头做练习:“今天的会议主要讨论了……”如果你补充“请写成给老板看的三条结论”,模型会沿着汇报方向生成;如果补充“请写成朋友圈文案”,它会换成轻松表达。上下文改变,下一句话的轨道就改变。
这也是为什么大模型很适合改写。改写不是凭空创造,而是在新约束下重新续写。你给出读者、语气、长度和格式,它就更容易生成符合场景的版本。
真实场景
如果你让模型把一句“我们这个功能很好用”改成面向不同读者的表达,它会沿着不同上下文续写:给工程师看,会强调实现和稳定性;给销售看,会强调客户收益;给老板看,会强调业务指标。看起来像理解受众,本质上是上下文改变了后续生成的概率。
这也解释了为什么示例很有用。你给一两个理想输出,模型就会沿着示例的风格和结构继续生成;你不给示例,它只能从通用模式里猜。
当你觉得模型“不懂我想要什么”时,往往不是它缺少情绪理解,而是缺少可模仿的上下文。给它一个好例子,通常比反复强调“写好一点”更有效。
示例就是把抽象要求变成可续写的轨道。
这也是普通人最容易掌握的大模型技巧之一。
延伸阅读
- GPT 路线的核心就是"预测下一个 token"——第 4 章:为什么 GPT 路线改变了世界讲了这条路线的来龙去脉
- 温度控制的是"从候选 token 里选谁",直接影响生成效果——第 9 章:温度与随机性
一句话总结
预测下一个 token 看似简单,但在海量文本训练后,它能学到语言、知识和任务结构;不过生成合理文本不等于事实自动正确。