核心问题
Agent 看起来很有吸引力:给它目标,它就能一步步做事。但为什么 Agent 也会失控?因为一旦模型进入“反复决策和调用工具”的循环,错误不再只是回答错一句话,而可能变成重复执行、用错工具、偏离目标,甚至伪造结果。
Agent 越能做事,越需要边界、停止条件和审计。
先建立直觉
想象你请一位实习生“帮我找三篇资料并整理摘要”。可靠的实习生会找资料、记录来源、发现资料不够时告诉你。失控的实习生可能一直搜索停不下来,也可能看到第一篇就偏题研究别的内容,甚至为了交差编出不存在的来源。
Agent 也是类似。它不是一次回答,而是多轮行动。每一轮都可能把小偏差放大。如果没有检查机制,系统可能越走越远。
概念拆解
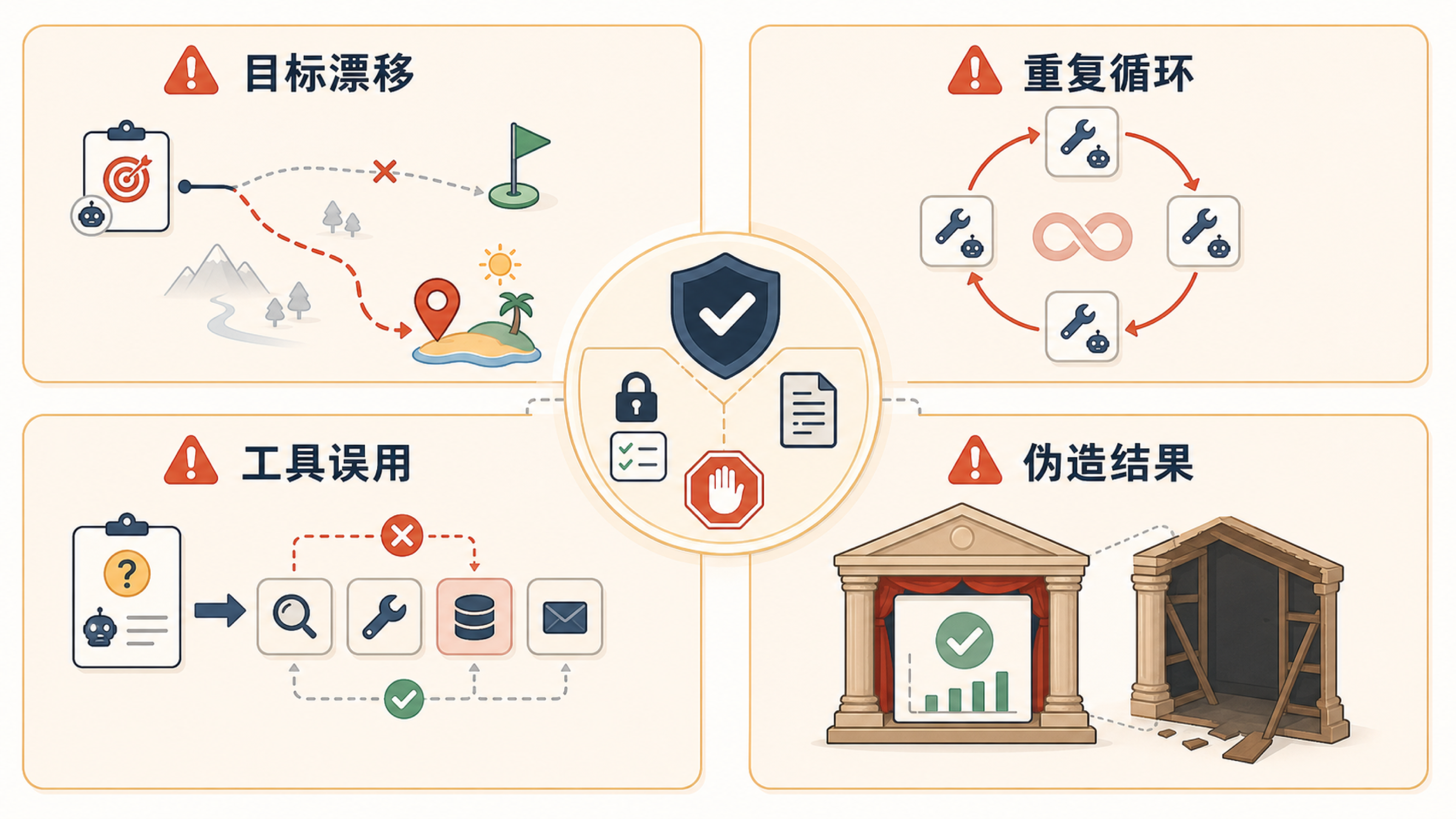
常见 Agent 失控有四类。
第一是目标漂移。原目标是“查天气”,执行中却开始规划旅行、推荐酒店,偏离用户真正需求。第二是重复循环。工具返回结果后,模型没有判断是否足够,于是反复搜索、反复尝试。第三是工具误用。把不该调用的工具用于当前任务,或者把草稿动作当成真实执行。第四是伪造结果。工具失败或无权限时,模型仍然生成一个看似成功的回答。
治理 Agent 的关键,是把目标、工具、权限、停止条件和日志都明确下来。不能只靠一句“请谨慎执行”。
互动理解
下面的调试台展示不同失控类型和对应修复手段。重点看:治理不是让 Agent 少做事,而是让它知道什么时候该停、该问人、该记录。
Agent 调试台
给失控的 Agent 加边界,观察它如何从循环中恢复。
当前问题:重复循环
反复调用搜索工具,却不判断答案是否已经足够。
对应修复:停止条件
限制同一工具最多连续调用 2 次,并在拿到足够信息后进入总结。
恢复后行为
第二次仍没有新增信息时,Agent 停止调用并说明信息不足。
失控轨迹
- 1调用搜索工具
- 2拿到相同摘要
- 3再次搜索同一个问题
- 4继续循环等待新结果
状态:当前失控类型仍未加边界。
常见误区
第一个误区是把 Agent 失控归因于模型“不够聪明”。更强模型可以减少一些错误,但没有边界的强模型仍然可能更快地做错事。
第二个误区是只加提示词,不加系统约束。提示词有帮助,但工具权限、调用次数、人工确认、日志审计必须由应用系统实现。
第三个误区是忽略失败报告。可靠 Agent 应该能说“我没有查到”“工具调用失败”“需要你确认”,而不是为了完成任务伪装成功。
实用方法
设计 Agent 时,至少要设置四道护栏。
第一,明确停止条件:完成什么算结束,最多尝试几次。第二,设置权限边界:哪些工具能用,哪些动作必须确认。第三,保留日志:每次调用的原因、输入和返回结果都要可追踪。第四,定义升级机制:遇到高风险、不确定或连续失败时交给人类。
普通用户使用 Agent 产品时,也要警惕“全自动完成一切”的宣传。越是能访问真实工具和数据的 Agent,越应该让你看到过程、确认关键动作、撤销错误结果。
自我检查
可以把 Agent 的每次执行看成一份可审计记录:它为什么调用这个工具?输入了什么参数?工具返回了什么?它根据结果做了什么判断?如果系统不能回答这些问题,问题发生后就很难定位责任。
治理 Agent 不只是开发者的事。普通用户也可以要求产品提供执行日志、暂停按钮、确认弹窗和权限开关。越自动化,越需要可见性。
真实场景
假设 Agent 要帮你“清理邮箱”。低风险做法是先分类并生成建议清单;中风险做法是把明显广告移动到文件夹;高风险做法是直接删除邮件或自动回复客户。每提高一级自动化,都应该增加确认和撤销能力。
很多失控不是一次大错误,而是一串小动作没有被及时发现。日志和停止按钮就是为了在小偏差变成大事故前打断流程。
如果你是产品负责人,可以把 Agent 的每个工具都写成权限表:谁能用、能用几次、是否需要确认、失败如何处理。这个表比一句“请安全执行”更可靠。
如果你是普通用户,也可以用同样思路管理自己的任务:先让 Agent 列计划,不让它直接执行;先看它准备调用哪些工具,再决定是否授权。授权应该是逐步给的,不是一次全开。
一旦任务涉及真实账户、客户、金钱、文件删除或外部发布,就应该默认需要确认,而不是默认自动执行。
这种默认值很重要。安全系统不能假设模型每次都判断正确,而要假设模型可能误判,然后通过权限、确认和日志把损失限制住。
好的默认值会把错误挡在小范围内。Agent 越强,越需要这种工程上的克制。
克制不是降低能力,而是让能力可控。
延伸阅读
- 回顾本单元的核心线索和关键收获 → 第五单元总结
- 治理 Agent 的前提是理解它的正常闭环——回到第 18 章:Agent巩固基础
- 每种失控类型背后往往有一个工具调用问题——回顾第 17 章:工具调用的权限与边界
一句话总结
Agent 失控通常不是因为它不会聊天,而是因为目标、工具、权限和停止条件没有被清楚约束。