核心问题
为什么有些人问 AI 得到的答案清楚、有用、可执行,有些人得到的却很泛、很虚、很难落地?差别不只在模型能力,也在问题是否给出了足够上下文和检查标准。
更好的提问,不是把 Prompt 写得像咒语,而是让模型知道:你是谁、要完成什么、有哪些边界、输出给谁看、结果如何判断好坏。
先建立直觉
想象你让同事“帮我写个总结”。他会问:总结哪份材料?给老板看还是给客户看?要一页还是三句话?重点是风险、进展还是下一步?如果这些都不说,对方只能凭猜测完成。
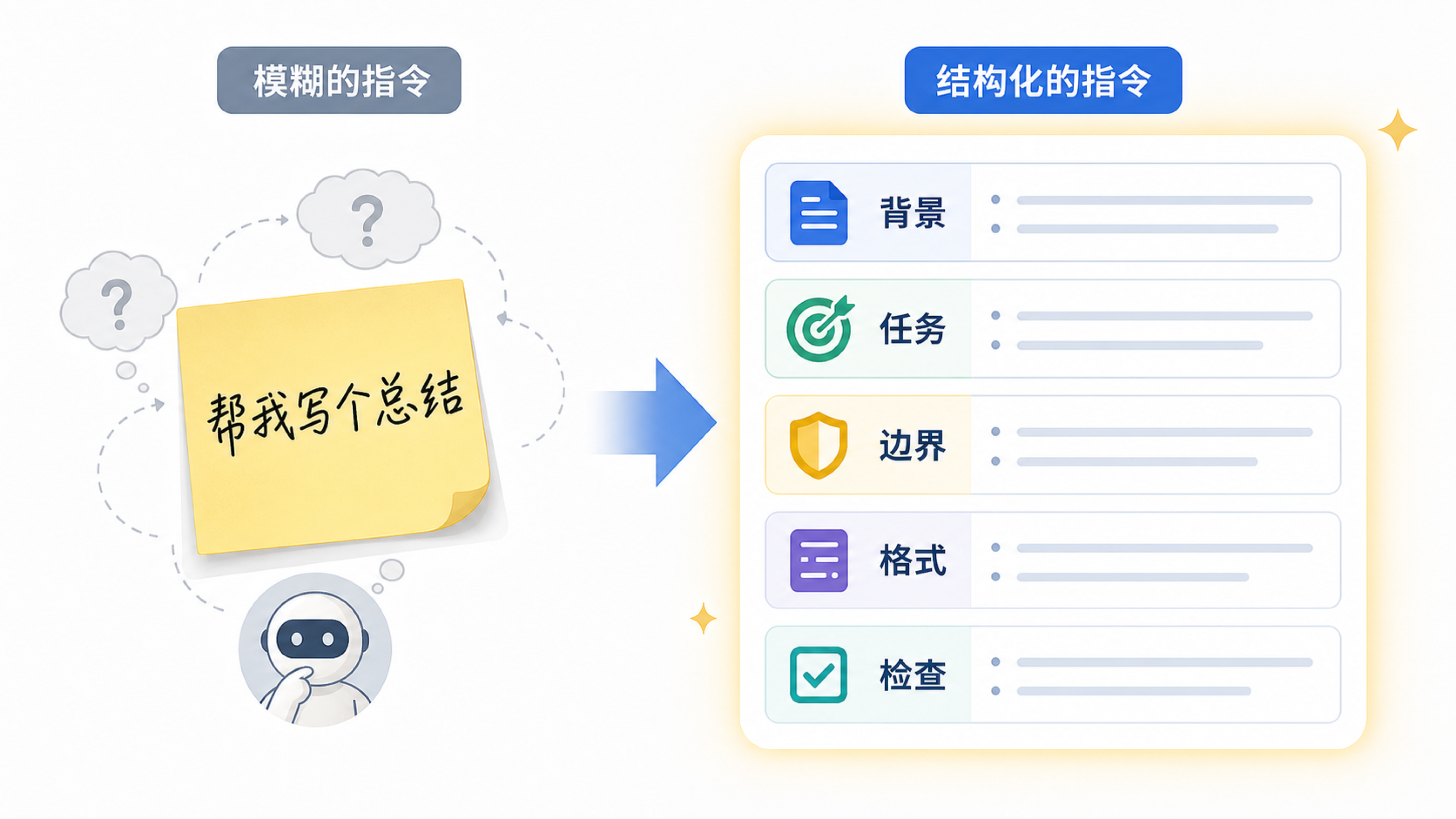
问模型也是一样。模糊问题会迫使模型猜你的目标,猜错后就会产生看似完整但不合用的答案。清楚问题不是让模型更听话,而是减少它需要猜的部分。
概念拆解
一个可检查的 Prompt 通常包含四类信息。
第一是背景:你在什么场景下使用答案,读者是谁。第二是任务:模型具体要做什么,是总结、改写、比较、提取还是生成。第三是边界:不要做什么,哪些信息不确定,哪些结论必须保守。第四是输出格式:列表、表格、步骤、JSON、邮件草稿还是提纲。
如果任务涉及事实,还应该加上检查要求。例如“请区分原文明确说的内容和你的推测”“引用依据句”“不确定时直接说明不知道”。这些要求会让答案更容易被人类复核。
互动理解
下面的组件会逐步展开可检查的推理步骤。你可以观察:把条件、顺序、计算和检查拆开后,错误更容易被发现。
可检查的推理步骤
逐步展开中间过程,让答案更容易被人类复核。
常见误区
第一个误区是相信万能 Prompt。没有一个提示词能适合所有任务。写总结、做计划、查事实、改代码、生成创意,需要的上下文和检查方式都不同。
第二个误区是 Prompt 越长越好。长 Prompt 如果堆满无关背景,会浪费上下文并干扰重点。好的 Prompt 是信息密度高,而不是字数多。
第三个误区是用命令语气替代质量标准。反复说“你必须认真”“不要出错”帮助有限。更有效的是告诉模型如何判断答案合格,例如“列出依据”“给出反例”“说明不确定性”。
实用方法
可以用一个简单模板开始:
你扮演的角色是什么?要完成的任务是什么?输入材料是什么?输出给谁看?必须遵守哪些边界?答案应该是什么格式?哪些地方需要标注不确定?
比如,不要只说“帮我分析这份报告”。可以说:“你是面向非技术管理者的产品顾问,请把这份用户访谈整理成 5 条主要痛点,每条包含原话证据、影响、建议动作。不要编造未出现的信息;不确定的地方单独列出。”
这样的提问不是为了讨好模型,而是为了让输出能被检查、复用和交付。
自我检查
把一个模糊问题改造成好问题,可以按“补四件事”练习:补读者、补目标、补边界、补格式。例如“帮我写一份方案”可以改成“面向部门负责人,用 800 字说明引入客服机器人试点的收益、风险和三周执行计划,风险部分必须包含人工兜底”。
如果你经常觉得 AI 回答“很空”,通常不是因为它不会写,而是因为你没有告诉它什么叫不空。给出判断标准,模型才知道该往哪里用力。
真实场景
同样是让 AI 写周报,“帮我写周报”会得到通用模板;“请根据以下 5 条进展,写给项目负责人看的周报,分为本周完成、风险、下周计划,每条不超过 40 字,风险必须给出负责人”就更可交付。后者不是更玄学,而是把读者、材料、结构和验收标准说清楚了。
一个好习惯是先让模型复述任务理解。如果复述都偏了,后面生成再长也不值得信任。
另一个好习惯是把“不要做什么”说清楚。比如“不要编造未提供的数据”“不要使用夸张营销语”“不要替医生下诊断”。这些边界会直接影响输出质量,也能提醒你自己哪些地方需要人工确认。
如果输出仍然不理想,不要只换模型。先检查 Prompt 是否缺少材料、读者、格式或验收标准。很多所谓模型能力问题,其实是任务描述没有进入上下文。
把好问题写清楚,本身就是一种工作能力。它会倒逼你明确目标,也会让团队对交付标准形成共识。
长期看,优秀的 Prompt 会沉淀成团队知识:新人可以复用,项目可以追踪,输出可以持续改进。它不是个人小技巧,而是流程资产。
流程资产越清晰,模型越稳定。
也越容易交接。
延伸阅读
- 本章的提问技巧直接服务于让推理更可检查——回顾第 10 章:推理
- Prompt 不只是提问,更是上下文控制——第 16 章:Prompt给出完整的 Prompt 编写框架
一句话总结
好 Prompt 的核心不是神奇措辞,而是给足上下文、边界和检查标准,让模型少猜、让人类好查。